考虑一个具有权重的N行数据集。这是基本算法:
玩具示例的问题在于随着
- 将权重归一化,使它们总和为1。
- 将权重备份到另一列中以记录样本概率
- 在给定样本概率的情况下,随机选择1行(不重复),并将其添加到样本数据集中
- 从原始数据集中删除所选权重,并通过将剩余行的权重归一化来重新计算样本概率
- 重复步骤3和4,直到样本中的权重总和达到或超过阈值(假设为0.6)
import pandas as pd
import numpy as np
def sampler(n):
df = pd.DataFrame(np.random.rand(n), columns=['weight'])
df['weight'] = df['weight']/df['weight'].sum()
df['samp_prob'] = df['weight']
samps = pd.DataFrame(columns=['weight'])
while True:
choice = np.random.choice(df.index, 1, replace=False, p=df['samp_prob'])[0]
samps.loc[choice, 'weight'] = df.loc[choice, 'weight']
df.drop(choice, axis=0, inplace=True)
df['samp_prob'] = df['weight']/df['weight'].sum()
if samps['weight'].sum() >= 0.6:
break
return samps
玩具示例的问题在于随着
n 的增加,运行时间呈指数级增长:
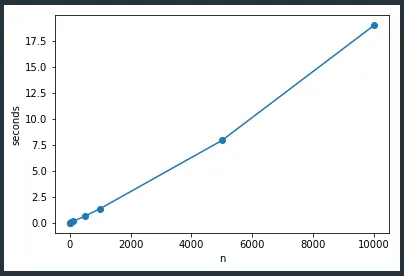
DataFrame(因为真实数据集有大约150列,并且在DataFrame中)。我得到了1000行的运行时间约为250毫秒。 - Kartik2/3?数据框架被认为是缓慢的,因此使用数组数据和掩码对我来说是有意义的。 - Divakarsampler2之间,我得到了大约2/3。仅使用掩码和预计算总和就提供了巨大的加速。在DataFrame中删除行是最耗费时间的。 - Kartiksampler4呢?在我这边看起来好像是最高效的。我想,如果你能像最初在问题中发布的那样,用一个漂亮的图形将sample1-4在同一图中展示出来,那会是一个很好的视角。 - Divakarsampler4具有最佳性能。我将编辑我的问题,包括所有版本的sampler的图表。通常,对于这样的算法,我会编写一个MWE,并在此处发布问题,如果我认为我需要一些额外的帮助,并且如果该问题会引起一些成员的兴趣。然后,我继续优化我的MWE,直到我对性能感到满意或者感到疲倦。使用掩码是显而易见的(它消除了第二个“DF”,并消除了“loc”扩展和“drop”),所以我这样做了,并在晚上称之为结束。而在早上,你的代码跑得最快! - Kartik