如果我有多个文本文件需要解析,看起来像这样,但是可能会因为列名和上面的标签长度而有所不同: 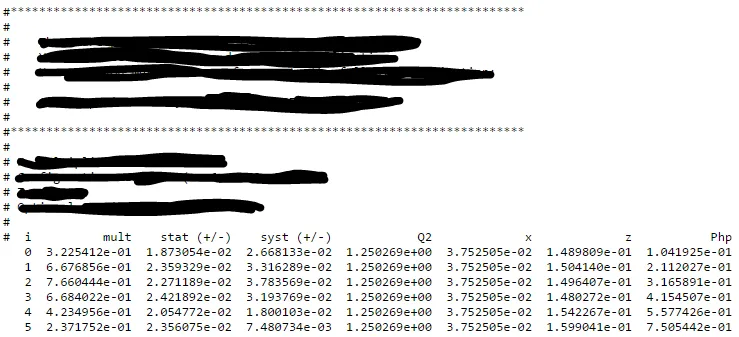 我该如何将其转换为 pandas 数据框? 我尝试使用
我该如何将其转换为 pandas 数据框? 我尝试使用
所有文本、星号和井号都需要被忽略,但是我不能只使用 skip rows,因为在另一个文件中,所有顶部的垃圾大小可能会变化。
由于空格,列 "stat (+/-)" 和 "syst (+/-)" 被视为 4 列。
一个井号包含在列名中,我不想要它。我不能只手动分配列名,因为它们会从文本文件到文本文件变化。
非常感谢任何帮助,读取文件后,我真的不确定该怎么做。
我该如何将其转换为 pandas 数据框? 我尝试使用pd.read_table('file.txt', delim_whitespace = True, skiprows = 14),但是出现了各种问题。我的问题如下:所有文本、星号和井号都需要被忽略,但是我不能只使用 skip rows,因为在另一个文件中,所有顶部的垃圾大小可能会变化。
由于空格,列 "stat (+/-)" 和 "syst (+/-)" 被视为 4 列。
一个井号包含在列名中,我不想要它。我不能只手动分配列名,因为它们会从文本文件到文本文件变化。
非常感谢任何帮助,读取文件后,我真的不确定该怎么做。