我有一个.xlsx文件,我可以使用以下方式成功读取:
pandas.read_excel(file_name, sheet_name="customers", index_col=0)
这适用于大多数列,但对于像“profile url”中字符之间有空格的列,则无法正常工作。这些列会被忽略。
编辑:以下是可重现此问题的部分代码:
import pandas as pd
def read_excel(file_name):
df = pd.read_excel(file_name, sheet_name="customers", index_col=0)
for entry in df.iterrows():
print(entry)
return df
read_excel("test_table.xlsx")
以下是一个使用示例表:
ID,First,Last,Profile Url
1,foo,bar,www.google.com
2,fake,name,https://stackoverflow.com/
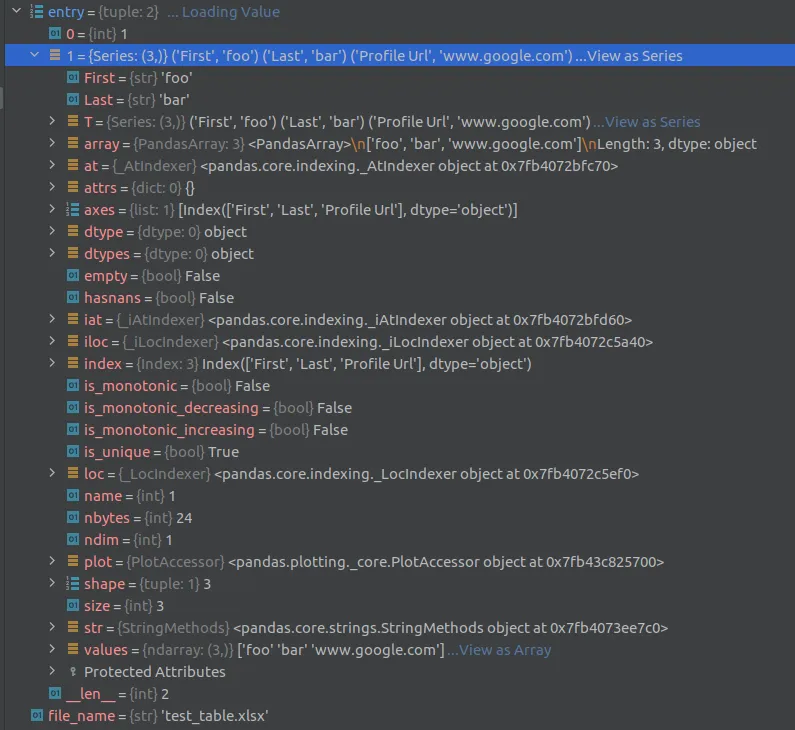
这是第一次迭代中 entry 值的内容。 这样做,我可以获得 First 和 Last 对象。
我希望也能看到 Profile Url。
通过准备这个示例,我学到了任何小写字母编写的标题也将被忽略。