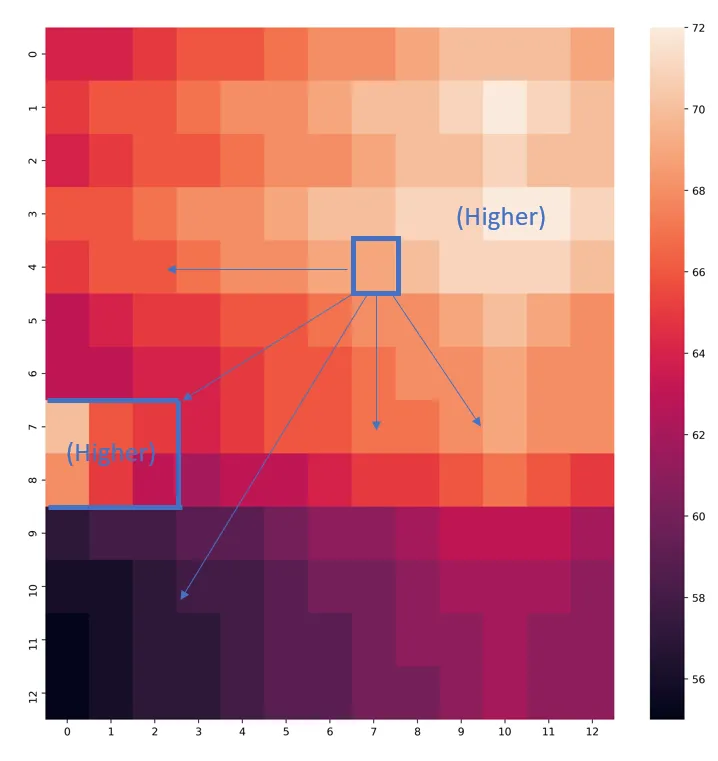
下面的2D numpy数组代表一个地形高度。从这个矩阵中的任意单元格开始,我希望找到那些可以通过不断向斜坡下方(高度更低)或平地移动到达的单元格。我们可以将其想象为模拟如果不允许球在另一侧的任何斜坡上回滚(无论多小),它可以可能滚动到的区域。请注意热图左侧的区域-它低于目标正方形,但仍需要爬上山才能到达那里。
如果数组是一维的,我可以想出一个不太优雅的解决方案,但是我认为可能有更优雅的解决方案可以扩展到二维?
import numpy as np
arr_surface_2D = np.array([
[64, 64, 65, 66, 66, 67, 68, 68, 69, 70, 70, 70, 69],
[65, 66, 66, 67, 68, 68, 69, 70, 70, 71, 72, 71, 70],
[64, 65, 66, 66, 67, 68, 68, 69, 70, 70, 71, 70, 70],
[66, 66, 67, 68, 68, 69, 70, 70, 71, 71, 72, 72, 71],
[65, 66, 66, 67, 68, 68, 69, 69, 70, 71, 71, 71, 70],
[63, 64, 65, 65, 66, 66, 67, 68, 68, 69, 70, 69, 68],
[63, 63, 64, 64, 65, 66, 66, 67, 68, 68, 69, 68, 68],
[70, 66, 65, 64, 65, 66, 66, 67, 67, 68, 69, 68, 68],
[68, 65, 63, 62, 63, 63, 64, 65, 65, 66, 67, 66, 65],
[57, 58, 58, 59, 59, 60, 61, 61, 62, 63, 63, 63, 62],
[56, 56, 57, 58, 58, 59, 60, 60, 61, 62, 62, 62, 61],
[55, 56, 57, 57, 58, 59, 59, 60, 61, 61, 62, 61, 61],
[55, 56, 57, 57, 58, 59, 59, 60, 60, 61, 62, 61, 61]
]
)
如果数组是一维的,我可以想出一个不太优雅的解决方案,但是我认为可能有更优雅的解决方案可以扩展到二维?
idx_target = 7
arr_surface_1D = np.array([
70, 66, 65, 64, 65, 66, 66, 67, # <-"target"
67, 68, 69, 68, 68])
# Slice array to the left side of idx_target, reverse direction to allow diff in next step
arr_left = arr_surface_1D[:idx_target][::-1]
# Determine number of spaces to the left where the values first start increasing
steps_left = np.argmax((np.diff(arr_left) > 0))
# Slice array to the right side of idx_target
arr_right = arr_surface_1D[idx_target + 1:]
# Determine number of spaces to the right where the values first start increasing
steps_right = np.argmax((np.diff(arr_right) > 0))
arr_downhill = arr_surface_1D[idx_target-(steps_left+1):idx_target+(steps_right)]
# Result is array array([64, 65, 66, 66])