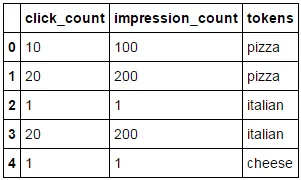
我希望能够对Panda数据框按单词进行聚合。
基本上有3列与相应短语的点击/印象计数。我想将短语拆分为标记,然后将它们的点击次数相加,以决定哪个标记相对较好/较差。
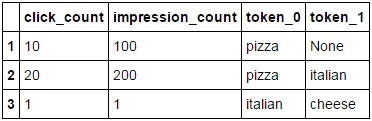
期望的输入:如下所示的Panda数据框
click_count impression_count text
1 10 100 pizza
2 20 200 pizza italian
3 1 1 italian cheese
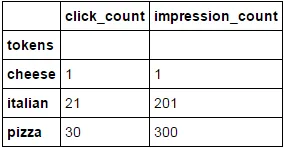
预期输出:
click_count impression_count token
1 30 300 pizza // 30 = 20 + 10, 300 = 200+100
2 21 201 italian // 21 = 20 + 1
3 1 1 cheese // cheese only appeared once in italian cheese