你遇到这个问题的原因是因为FFT隐含地假设提供的输入信号是周期性的。如果你重复你的原始数据,你会发现每个周期都有一个大的不连续性(当信号从约20回落到约5时)。一旦去除了一些高频分量,你就会看到边缘处略微不太锐利的不连续性(在开头和结尾各几个样本)。
为了避免这种情况,你可以使用线性FIR滤波器在时间域中进行过滤,这可以在不考虑周期性假设的情况下处理数据序列。
对于这个答案的目的,我构建了一个合成测试信号(你可以用它来重新创建相同的条件),但你显然可以使用自己的数据。
fs = 1
f0 = 0.002/fs
f1 = 0.01/fs
dt = 1/fs
t = np.arange(200, 901)*dt
m = (25-5)/(t[-1]-t[0])
phi = 4.2
x = 5 + m*(t-t[0]) + 2*np.sin(2*np.pi*f0*t) + 1*np.sin(2*np.pi*f1*t+phi) + 0.2*np.random.randn(len(t))
现在,为了设计滤波器,我们可以对
_mask取逆变换(而不是应用该掩模):
import numpy as np
def freq_sampling_filter(x, threshold):
n = len(x)
fft = np.fft.fft(x, n)
PSD = fft * np.conj(fft) / n
_mask = PSD > threshold
_coff = np.fft.fftshift(np.real(np.fft.ifft(_mask)))
return _coff
coff = freq_sampling_filter(x, threshold)
“阈值”是一个可调参数,应该选择它来保留你想要的足够频率成分并摆脱不需要的频率成分。当然这是高度主观的。
然后我们可以简单地使用
scipy.signal.filtfilt函数应用过滤器:
from scipy.signal import filtfilt
cleaned = filtfilt(coff, 1, x, padlen=len(x)-1, padtype='constant')
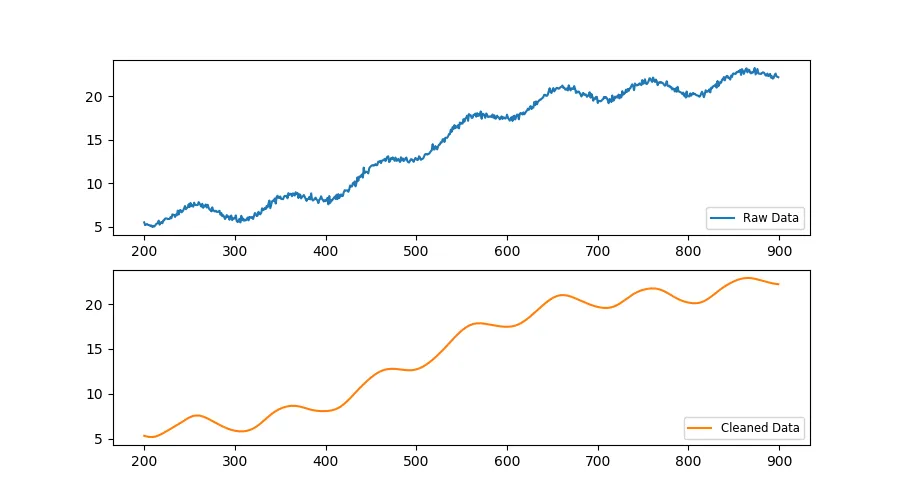
为了说明,使用上述生成的合成信号的阈值10会产生以下原始数据(变量x)和清理后数据(变量cleaned):
{{link1:
}}
选择padtype为'constant'可以确保过滤后的值从未过滤的数据的起始和结束值开始和结束。
替代方法:
正如在评论中发布的那样,对于更长的数据集,filtfilt可能会很昂贵。
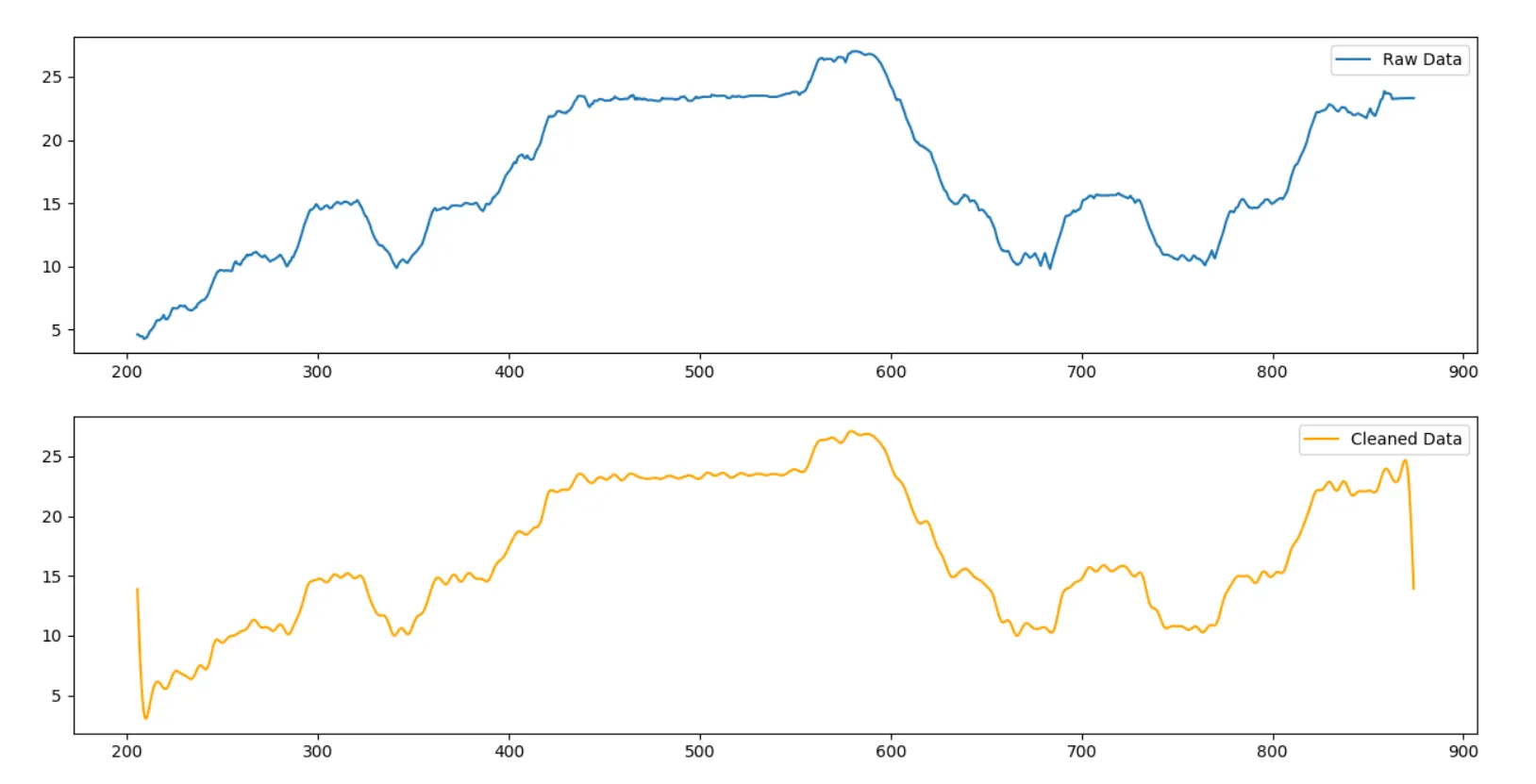
作为替代方案,可以使用基于FFT的卷积来执行过滤,方法是使用scipy.fftconvolve。请注意,在这种情况下,没有与filtfilt的padtype参数相当的东西,因此我们需要手动填充信号以避免在开头和结尾出现边缘效应。
n = len(x)
x_padded = np.concatenate((x[0]*np.ones(n-1), x, x[-1]*np.ones((n-1)//2)))
cleaned = fftconvolve(x_padded, coff, mode='same')
cleaned = cleaned[2*(n-1)//2:-n//2+1]
供参考,以下是长度为700的上述信号的一些基准比较(时间以秒为单位,因此越小越好):
filtfilt : 0.3831593
fftconvolve : 0.00028040000000029153
请注意,相对性能会有所不同,但是基于FFT的卷积在信号长度较长时预计会表现得更好。
filtfilt,因为您没有提到大型数据集,这使得解决方案更简单。但是我相信对于奇数的n,您可以在开头添加n-1次第一个值,并在结尾添加另外(n-1)/2次最后一个值,然后使用fftconvolve并且摆脱前面的3*(n-1)/2个输出。如果有机会,我可能会将其变成官方答案/更新。 - SleuthEyefreq_sampling_filter函数中的threshold是什么?还是你想写成n_components?为了重现结果,在你创建测试原始数据时,该函数参数使用的值是多少? - msh855threshold值。尽管如此,我使用变量threshold是因为我认为它更符合FFT值高于该阈值时保留的思想,而不是OP的fft_denoiser函数参数的n_components,这表明保留指定数量的频率分量。 - SleuthEye