最近我在scipy.special.legendre() (scipy文档) 中遇到了一个奇怪的问题。Legendre多项式应该是成对正交的。但是,当我计算它们在x=[-1,1]范围内的值,并且计算不同次数的两个多项式的标量积时,我并不总是得到零或接近零的值。我是否误解了这个函数的行为?
下面是一个简短的示例,可以生成某些Legendre多项式的标量积:
from __future__ import print_function, division
import numpy as np
from scipy import special
import matplotlib.pyplot as plt
# create range for evaluation
x = np.linspace(-1,1, 500)
degrees = 6
lp_array = np.empty((degrees, len(x)))
for n in np.arange(degrees):
LP = special.legendre(n)(x)
# alternatively:
# LP = special.eval_legendre(n, x)
lp_array[n, ] = LP
plt.plot(x, LP, label=r"$P_{}(x)$".format(n))
plt.grid()
plt.gca().set_ylim([-1.1, 1.1])
plt.legend(fontsize=9, loc="lower right")
plt.show()
单项式的图像实际上看起来不错:
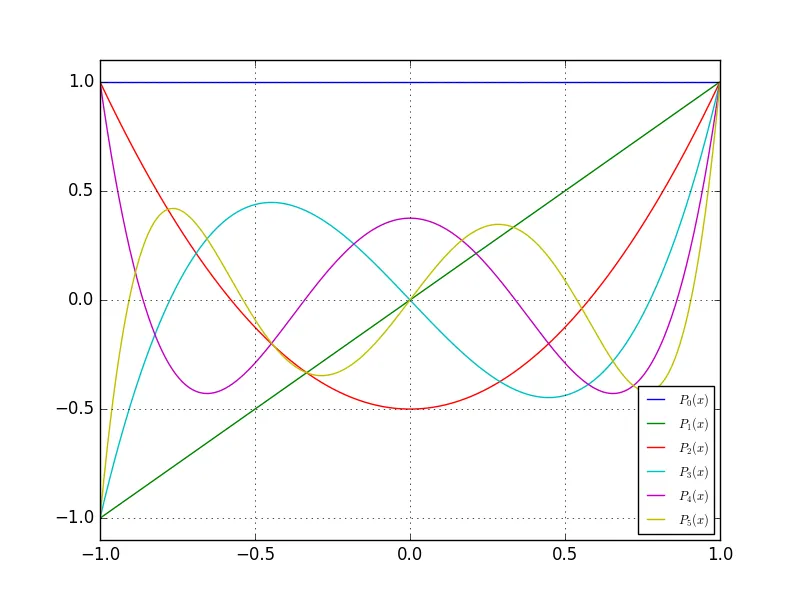 但如果我手动计算标量积——逐个元素相乘两个不同次数的Legendre多项式并将它们加起来(500用于归一化)……
但如果我手动计算标量积——逐个元素相乘两个不同次数的Legendre多项式并将它们加起来(500用于归一化)……for i in range(degrees):
print("0vs{}: {:+.6e}".format(i, sum(lp_array[0]*lp_array[i])/500))
我得到以下值作为输出:
0vs0: +1.000000e+00
0vs1: -5.906386e-17
0vs2: +2.004008e-03
0vs3: -9.903189e-17
0vs4: +2.013360e-03
0vs5: -1.367795e-16
第一个多项式与自身的数量积(如预期)等于1,而另一半结果几乎为零,但是有一些值在10e-3的数量级,我不知道为什么。我还尝试了
scipy.special.eval_legendre(n, x)函数,结果相同:-\ 是否这是scipy.special.legendre()函数中的一个错误?或者我做错了什么?我正在寻找建设性的回应:-) 问候,马库斯
10^{-3} ~ 1/500是在使用500个点时你所期望的误差数量级。 - pv.scipy.special.legendre来说,这显然太短了,无法得到适当的正交多项式。然而,这会导致在计算协方差矩阵时出现不同的方差值,具体取决于我考虑多少个勒让德多项式。有没有办法解决这个问题? - Markus