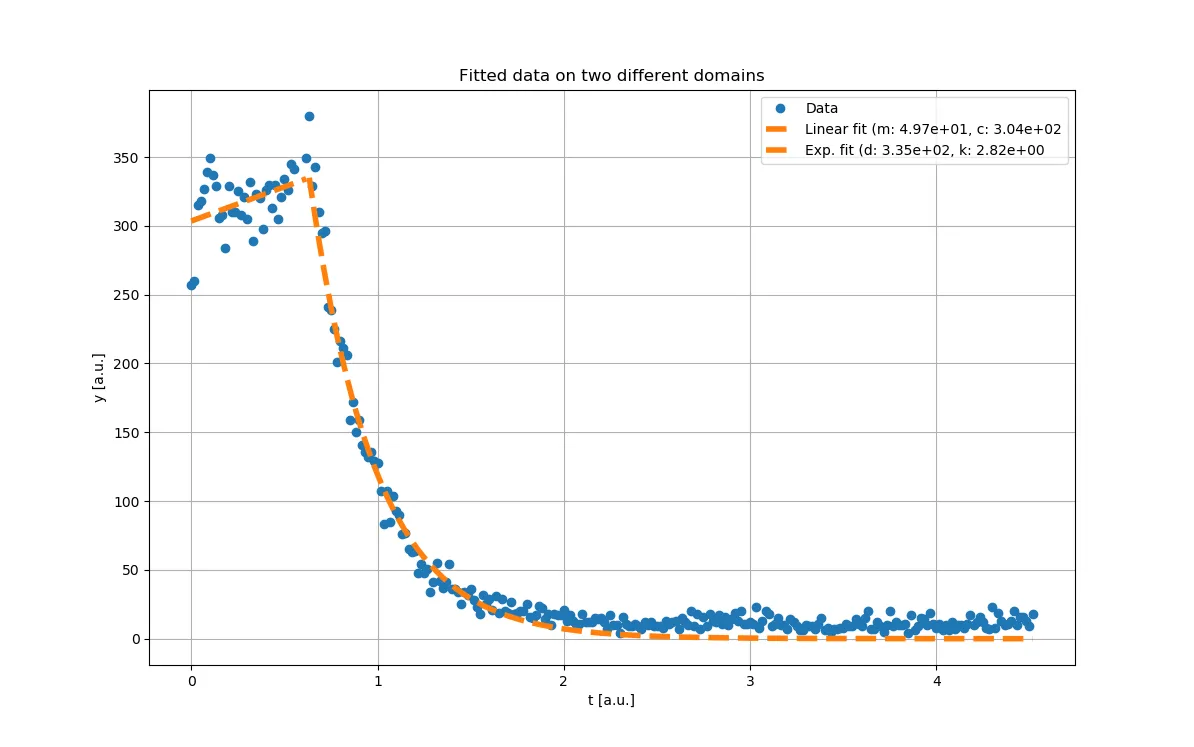
由于您的数据在不同地区呈现出不同的行为,因此您还需要将数据拟合到这些不同的区域。即,与其对两个模型(函数)求和,您应该使用y = m*x + c在左侧区域单独进行拟合,在右侧区域单独使用y = d*exp(-k*x)进行拟合。如果您难以找到两个区域的边界,可以通过比较拟合优度来评估。
popt_1, pcov_1 = curve_fit(lambda x, m, c: m*x + c, t[t < 0.8], y[t < 0.8], p0=(1, 0))
popt_2, pcov_2 = curve_fit(lambda x, d, k: d*exp(-k*x), t[t >= 0.8], y[t >= 0.8], p0=(400, 1))
编辑
示例代码:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy.optimize import curve_fit
df = pd.read_csv('test.csv', index_col=None)
t = df.t.values
y = df.Y.values
boundary = t[y.argmax()]
t1 = t[t < boundary]
y1 = y[t < boundary]
t2 = t[t >= boundary]
y2 = y[t >= boundary]
f1 = lambda x, m, c: m*x + c
f2 = lambda x, d, k: d*np.exp(-k*x)
popt_1 ,pcov_1 = curve_fit(f1, t1, y1, p0=((y1[-1] - y1[0]) / (t1[-1] - t1[0]), y1[0]))
popt_2 ,pcov_2 = curve_fit(f2, t2, y2, p0=(y2[0], 1))
plt.title('Fitted data on two different domains')
plt.xlabel('t [a.u.]')
plt.ylabel('y [a.u.]')
plt.plot(t, y, '-o', label='Data')
plt.plot(t1, f1(t1, *popt_1), '--', color='#ff7f0e', lw=3, label='Fit')
plt.plot(t2, f2(t2, *popt_2), '--', color='#ff7f0e', lw=3, label='_nolegend_')
plt.grid()
plt.legend()
plt.show()
这将产生以下图表:
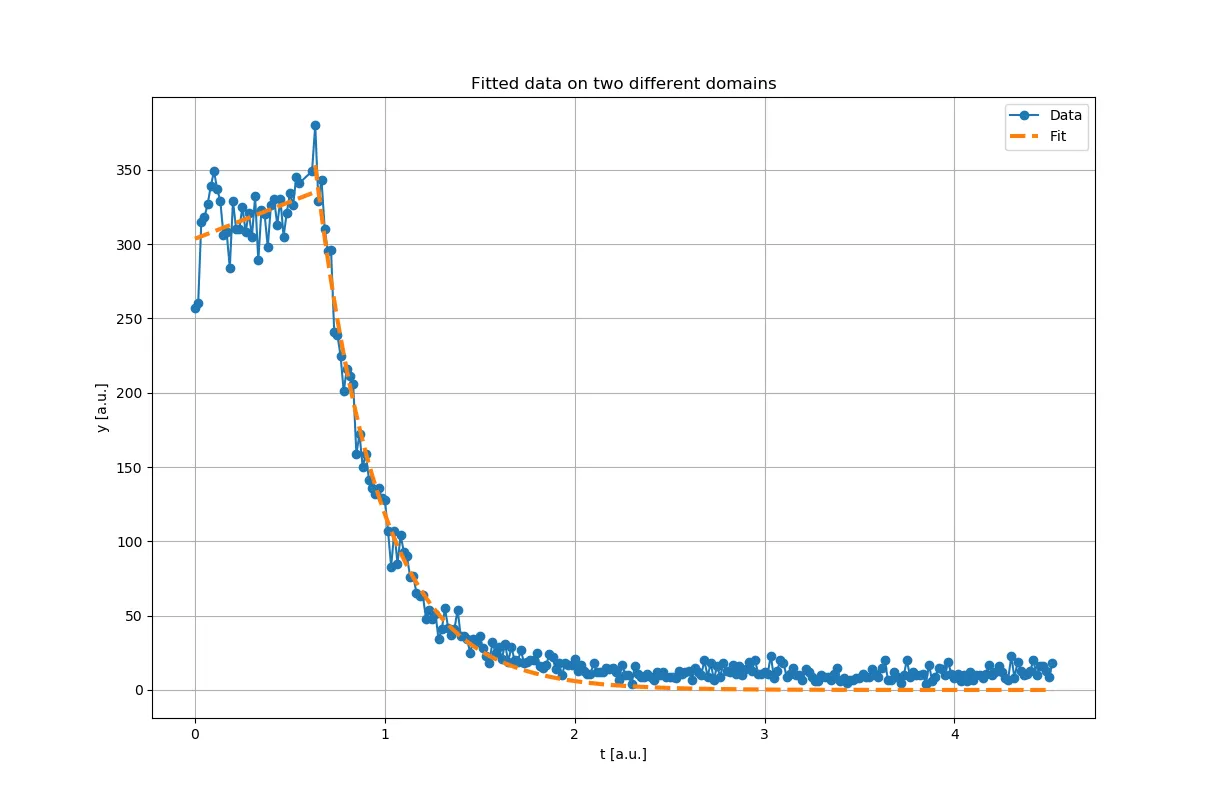
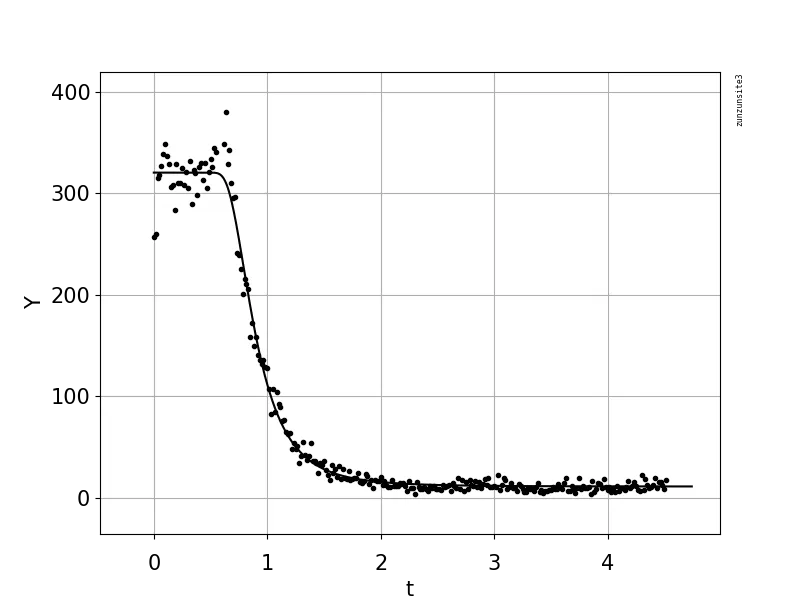
请注意,生成的“复合”函数在边界处不连续。如果不希望出现这种情况,您可以在拟合另一个域之前修复一个拟合参数(例如k)。或者,您可以分别拟合两个区域,然后确定边界处的值为两个单独函数的平均值(即y_b = (f1(t1[-1], *popt_1) + f2(t2[0], *popt_2)) / 2),然后通过约束参数来重复拟合,以满足此边界条件。
例如,首先拟合线性函数,然后固定指数中的d参数,以使边界处具有连续性(请注意,线性函数f1会在t2[0]处进行外推,以确保连续性):
f1 = lambda x, m, c: m*x + c
popt_1, pcov_1 = curve_fit(f1, t1, y1, p0=((y1[-1] - y1[0]) / (t1[-1] - t1[0]), y1[0]))
d = f1(t2[0], *popt_1)
f2 = lambda x, k: d*np.exp(-k*(x - boundary))
popt_2, pcov_2 = curve_fit(f2, t2, y2, p0=(1,))
这将生成以下图表: