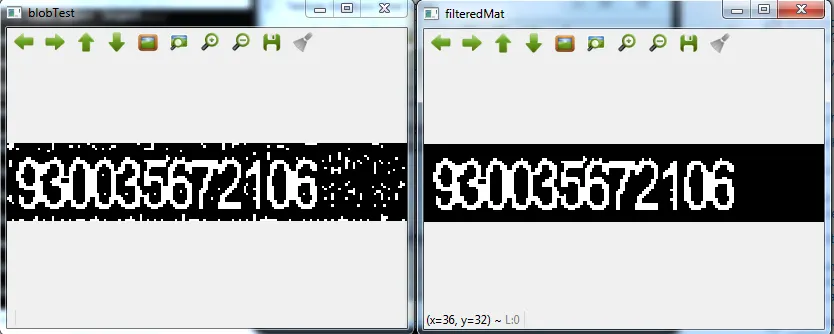
我收到了一些需要处理的图像,以便从中OCR出一些信息。以下是原始图像:
原始图像1
 原始图像2
原始图像2
 原始图像3
原始图像3
 原始图像4
原始图像4
 使用以下代码进行处理:
使用以下代码进行处理:
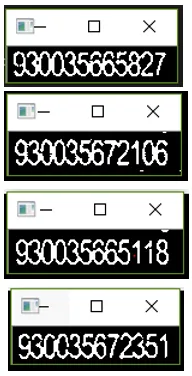
我得到了以下结果: 结果1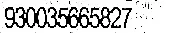 结果2
结果2
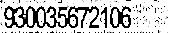 结果3
结果3
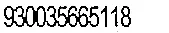 结果4
结果4
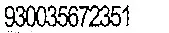 可以看出,有些图片在OCR阅读时效果很好,而其他一些则仍保留了一些背景噪声。
可以看出,有些图片在OCR阅读时效果很好,而其他一些则仍保留了一些背景噪声。
是否有任何建议如何清除背景噪声?
原始图像2
原始图像3
原始图像4
使用以下代码进行处理:img = cv2.imread('original_1.jpg', 0)
ret,thresh = cv2.threshold(img,55,255,cv2.THRESH_BINARY)
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, cv2.getStructuringElement(cv2.MORPH_RECT,(2,2)))
cv2.imwrite('result_1.jpg', opening)
我得到了以下结果: 结果1
结果2
结果3
结果4
可以看出,有些图片在OCR阅读时效果很好,而其他一些则仍保留了一些背景噪声。是否有任何建议如何清除背景噪声?