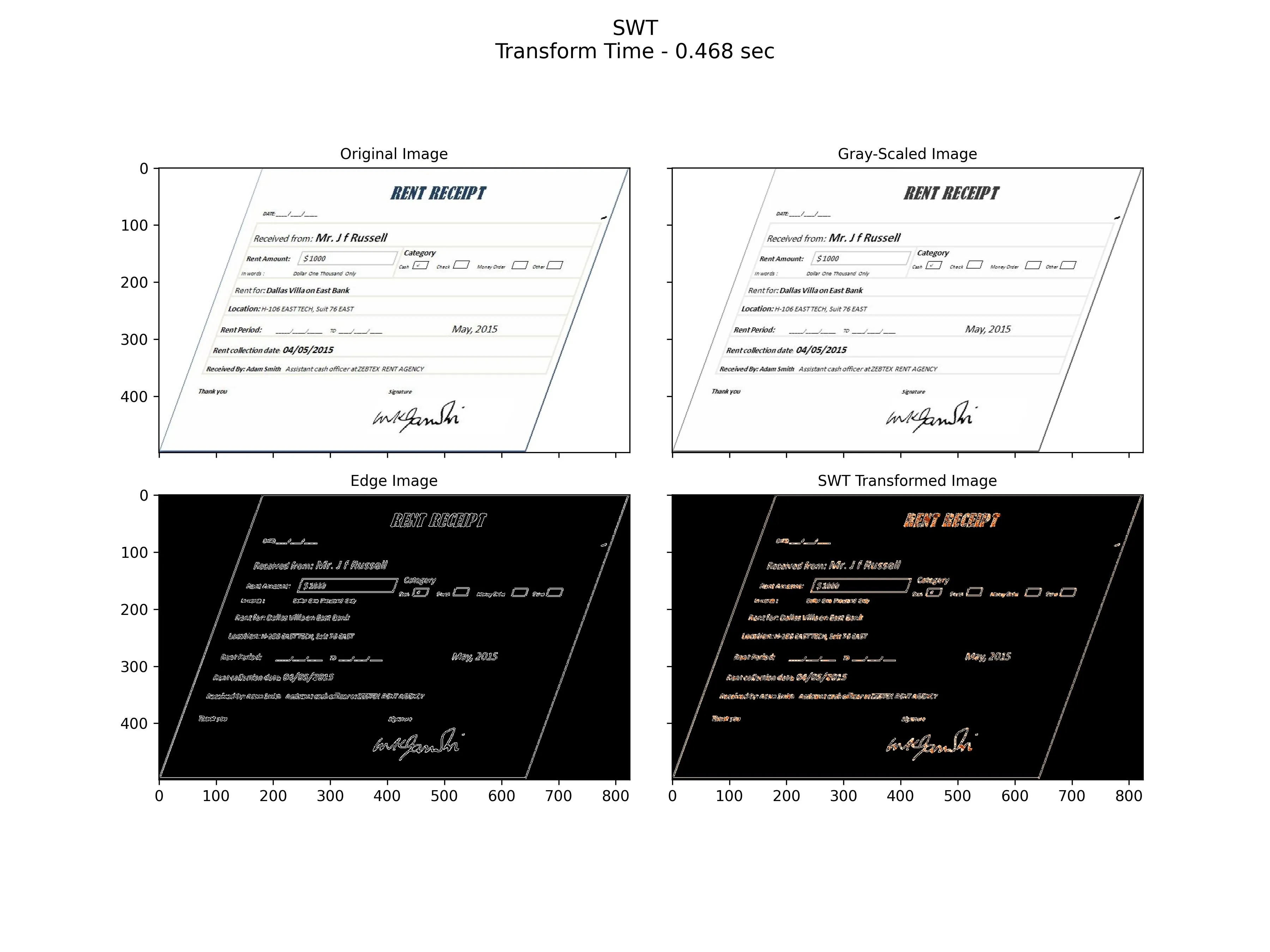
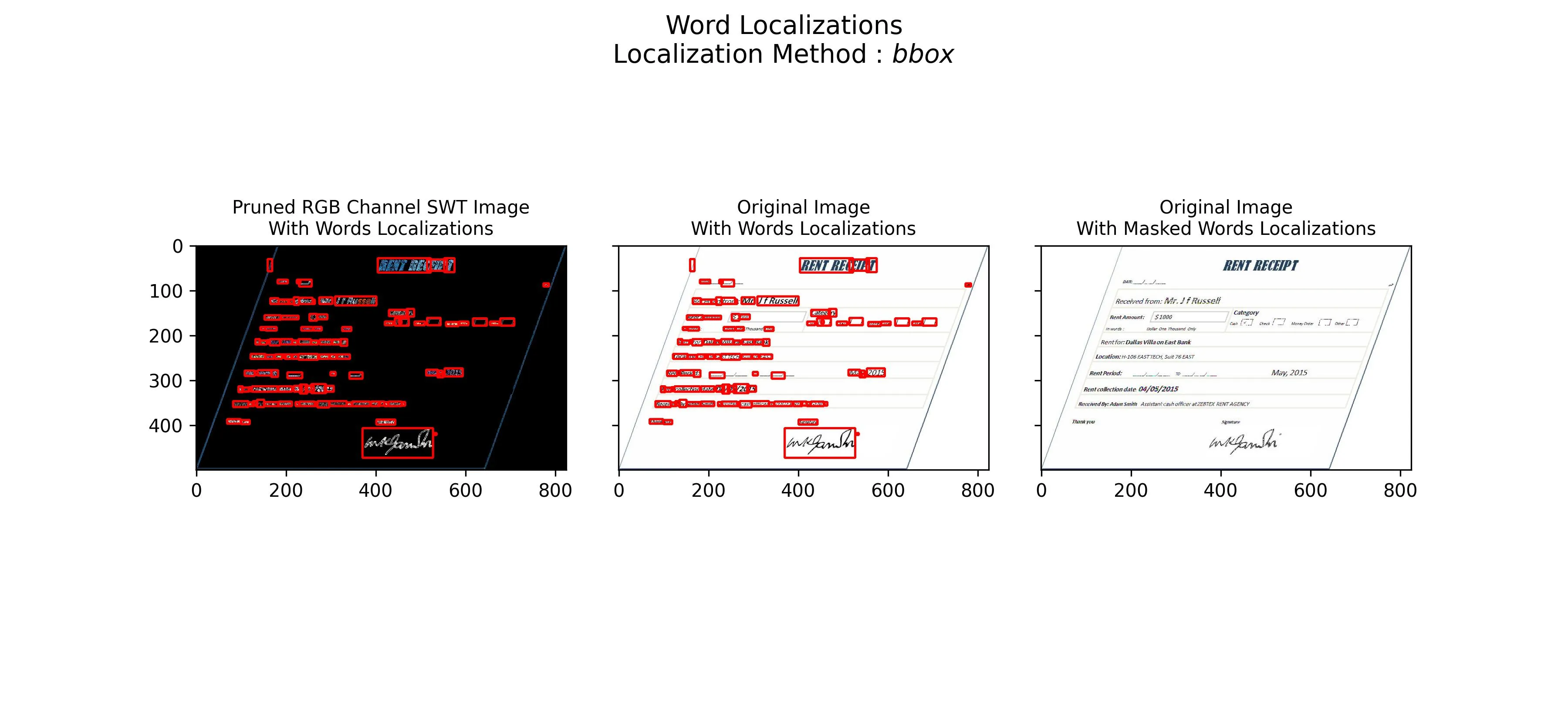
我正在尝试从这个小票的玩具示例中进行OCR。使用Python 2.7和OpenCV 3.1。

灰度+模糊+外部边缘检测+对小票每个区域进行分割(例如“分类”,以后可以查看哪一个被标记了-在这种情况下是现金)。
当图像“倾斜”时,我发现能够正确变换并“自动”分割小票的每个部分非常复杂。
例如:

有什么建议吗?
以下代码是获取边缘检测的示例,但当小票像第一张图片那样时,我的问题不是将图像转换为文本,而是图像的预处理。
超出任何帮助都将不胜感激! :)
import os;
os.chdir() # Put your own directory
import cv2
import numpy as np
image = cv2.imread("Rent-Receipt.jpg", cv2.IMREAD_GRAYSCALE)
blurred = cv2.GaussianBlur(image, (5, 5), 0)
#blurred = cv2.bilateralFilter(gray,9,75,75)
# apply Canny Edge Detection
edged = cv2.Canny(blurred, 0, 20)
#Find external contour
(_,contours, _) = cv2.findContours(edged, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)