这里有一个想法。我们将这个问题分成几个步骤:
1. 确定矩形轮廓的平均面积。我们进行阈值处理,然后找到轮廓并使用轮廓的边界矩形面积进行过滤。我们之所以这样做,是因为观察到任何典型的字符只会那么大,而大噪声将跨越更大的矩形区域。然后我们确定平均面积。
2. 删除大的异常轮廓。我们再次迭代轮廓,并通过填充轮廓来删除大的轮廓,如果它们比平均轮廓面积大5倍。我们不使用固定的阈值面积,而是使用这个动态阈值来提高鲁棒性。
3. 用垂直核膨胀以连接字符。这个想法是利用字符在列中对齐的观察结果。通过用垂直核膨胀,我们将文本连接在一起,因此噪声将不包括在这个组合轮廓中。
4. 删除小的噪声。现在保留的文本已经连接了,我们找到轮廓并删除任何小于平均轮廓面积4倍的轮廓。
5. 位运算重构图像。由于我们只在掩模上保留所需的轮廓,因此我们进行位运算以保留文本并得到结果。
这是一个过程的可视化:
我们使用
大津阈值 获得二进制图像,然后
查找轮廓 来确定平均矩形轮廓面积。从这里开始,我们通过
填充轮廓 来去除被突出显示为绿色的大离群轮廓。


下一步,我们构建一个
垂直卷积核并进行
膨胀操作以连接字符。此步骤将所有需要保留的文本连接起来,并将噪声隔离为单独的块。
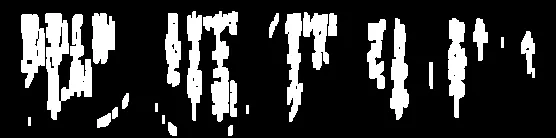
现在我们找到轮廓并使用
轮廓面积进行过滤,以消除小噪声。
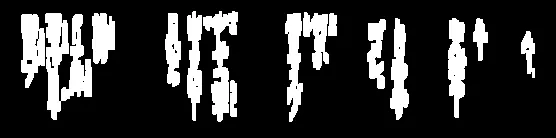
这里是所有被去除的噪点,用绿色标出

结果

代码
import cv2
image = cv2.imread('1.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
average_area = []
cnts = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
for c in cnts:
x,y,w,h = cv2.boundingRect(c)
area = w * h
average_area.append(area)
average = sum(average_area) / len(average_area)
cnts = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
for c in cnts:
x,y,w,h = cv2.boundingRect(c)
area = w * h
if area > average * 5:
cv2.drawContours(thresh, [c], -1, (0,0,0), -1)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2,5))
dilate = cv2.dilate(thresh, kernel, iterations=3)
cnts = cv2.findContours(dilate, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
for c in cnts:
area = cv2.contourArea(c)
if area < average * 4:
cv2.drawContours(dilate, [c], -1, (0,0,0), -1)
result = cv2.bitwise_and(image, image, mask=dilate)
result[dilate==0] = (255,255,255)
cv2.imshow('result', result)
cv2.imshow('dilate', dilate)
cv2.imshow('thresh', thresh)
cv2.waitKey()
注意: 传统图像处理仅限于阈值处理、形态学操作和轮廓过滤(轮廓近似、面积、长宽比或斑点检测)。由于输入图像可能会根据字符文本大小而变化,因此找到一个单一的解决方案是相当困难的。您可能需要研究使用机器/深度学习训练自己的分类器以获得动态解决方案。
