到目前为止,Step Functions看起来是最好的选择。
使用Step Functions,我们可以拥有以下图形:
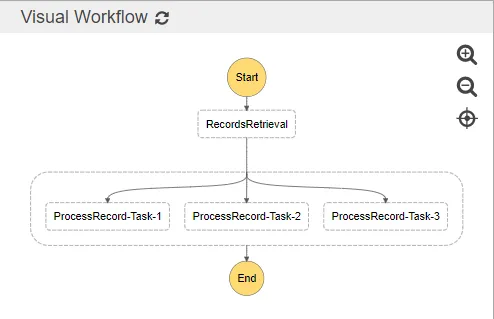
我可以将RecordsRetrieval定义为一个任务。之后,这些记录将由ProcessRecords-Task-1、ProcessRecords-Task-2和ProcessRecords-Task-3的任务并行处理。看起来一切都很好,对吗?错了!
第一个问题:动态缩放 如果我想要对这些任务进行动态缩放(比如...10、100、5k或10k),考虑要处理的记录数量,我将不得不动态构建json以实现该目的(这不是一个非常优雅的解决方案,但它可能起作用)。我非常有信心任务数量有一个限制,所以我不能依赖它。如果扩展重负是由基础架构而不是由我处理,那将会更好。
无论如何,对于像GetAddress、GetPhoneNumber、GetWhatever这样明确定义的一组并行任务来说,这是非常好的!完美运作!
第二个问题:有效载荷分发 在RecordsRetrieval任务之后,我需要单独处理每个记录。使用Step Functions,我没有看到任何实现这一点的方法。一旦RecordsRetrieval任务传递其有效载荷(在本例中为这些记录),所有并行任务都将处理相同的有效载荷。
再次强调,对于像GetAddress、GetPhoneNumber、GetWhatever这样明确定义的一组并行任务来说,这将是完美的匹配。
结论 我认为,可能AWS Step Functions不是我的场景的解决方案。这是我对它的了解的总结,所以如果我漏掉了什么,请随时评论。
我正在研究微服务方法,原因有很多(可扩展性、无服务器、简单等)。
我知道可以检索这些记录并将其逐个发送到另一个lambda,但再次强调,这不是一个非常优雅的解决方案。
我也知道这是批处理作业,AWS有批处理服务。我正在尝试保持微服务方法,而不依赖于AWS Batch/EC2。
你对此有何看法?欢迎留言评论。任何建议都将不胜感激。