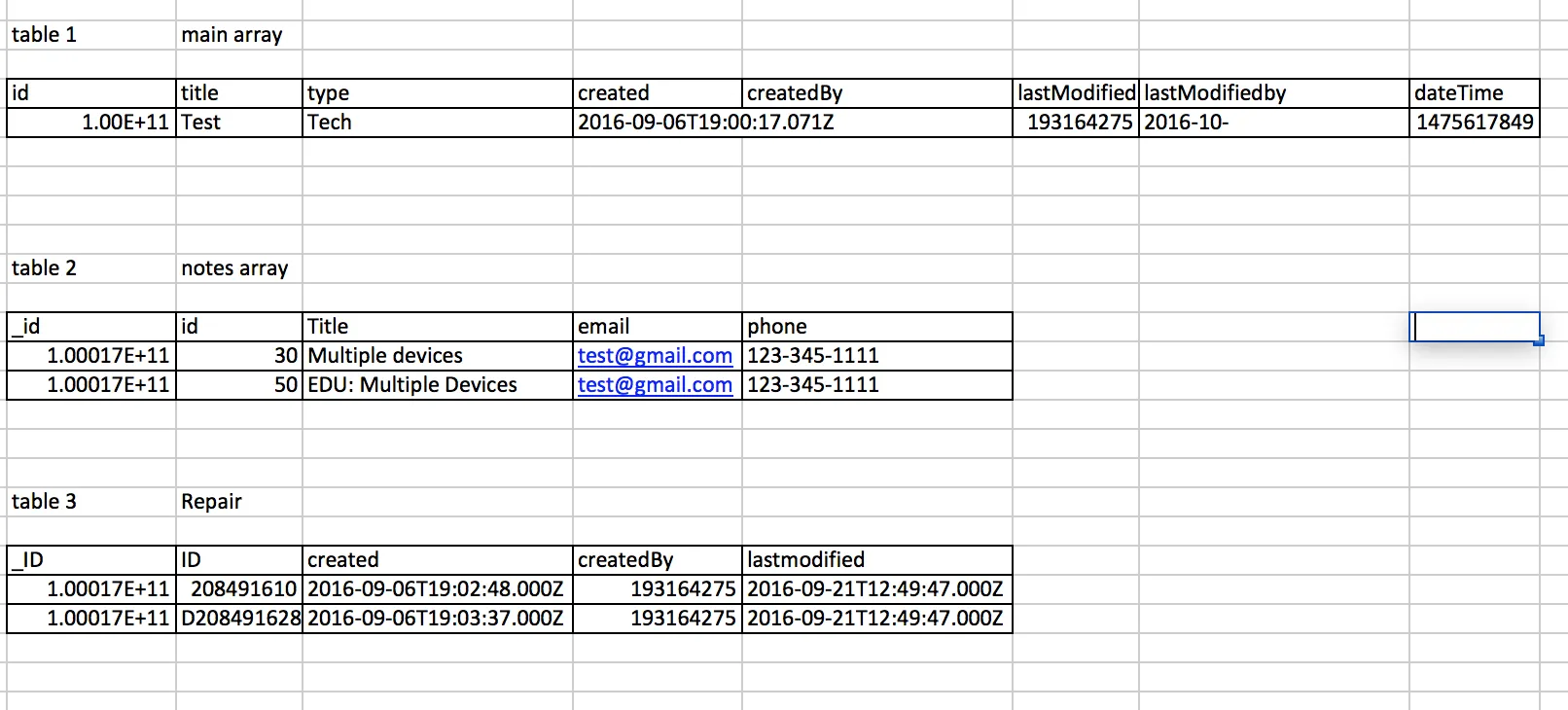
我有一个嵌套的JSON,如下所示,并希望在Python中解析成多个数据框架..请帮忙。
{
"tableName": "cases",
"url": "EndpointVoid",
"tableDataList": [{
"_id": "100017252700",
"title": "Test",
"type": "TECH",
"created": "2016-09-06T19:00:17.071Z",
"createdBy": "193164275",
"lastModified": "2016-10-04T21:50:49.539Z",
"lastModifiedBy": "1074113719",
"notes": [{
"id": "30",
"title": "Multiple devices",
"type": "INCCL",
"origin": "D",
"componentCode": "PD17A",
"issueCode": "IP321",
"affectedProduct": "134322",
"summary": "testing the json",
"caller": {
"email": "katie.slabiak@spps.org",
"phone": "651-744-4522"
}
}, {
"id": "50",
"title": "EDU: Multiple Devices - Lightning-to-USB Cable",
"type": "INCCL",
"origin": "D",
"componentCode": "PD17A",
"issueCode": "IP321",
"affectedProduct": "134322",
"summary": "parsing json 2",
"caller": {
"email": "testing1@test.org",
"phone": "123-345-1111"
}
}],
"syncCount": 2316,
"repair": [{
"id": "D208491610",
"created": "2016-09-06T19:02:48.000Z",
"createdBy": "193164275",
"lastModified": "2016-09-21T12:49:47.000Z"
}, {
"id": "D208491610"
}, {
"id": "D208491628",
"created": "2016-09-06T19:03:37.000Z",
"createdBy": "193164275",
"lastModified": "2016-09-21T12:49:47.000Z"
}
],
"enterpriseStatus": "8"
}],
"dateTime": 1475617849,
"primaryKeys": ["$._id"],
"primaryKeyVals": ["100017252700"],
"operation": "UPDATE"
我希望解析这个并创建如下三个表/数据框/CSV。。请帮忙。
{kind=link}