有没有一个选择Java集合接口(如List、Map或Set)不同实现的好方法?
例如,通常在什么情况下我会更喜欢使用Vector或ArrayList、Hashtable或HashMap等。
有没有一个选择Java集合接口(如List、Map或Set)不同实现的好方法?
例如,通常在什么情况下我会更喜欢使用Vector或ArrayList、Hashtable或HashMap等。
我假设您已经从以上答案中了解了List、Set和Map的区别。为什么要选择它们的实现类又是另一回事。例如:
List:
Set:
Map: HashMap和TreeMap的性能和行为与Set实现相同。
Vector和Hashtable不应该使用。它们是在新的Collection层次结构发布之前同步实现,因此速度较慢。如果需要同步,请使用Collections.synchronizedCollection()。
add(int, E) 在给定的索引位置插入和使用 add(E) 在任何位置插入的区别。ArrayList 在数组末尾添加元素不慢(除非需要扩展支撑数组时),而LinkedList在后一种情况下也不会慢。 - artbristol我总是根据具体情况做出决策,例如:
接着我会拿出我方便的第五版《Java核心技术》并比较大约20个选项。在第五章中,它有一些漂亮的小表格可以帮助人们找到合适的选择。
好吧,也许如果我知道一个简单的ArrayList或HashSet会解决问题,我就不会再查了。;)但是,如果我的使用场景稍微有点复杂,我肯定会翻书。顺便说一下,我认为Vector应该是“老古董”了-我已经好几年没用过了。
就理论而言,大O符号是有用的折衷方案,但在实践中几乎从来不重要。
在真实世界的基准测试中,ArrayList即使对于大型列表和“靠近前面的大量插入”等操作也会优于LinkedList。学者们忽略了真正算法的常数因子可能会压倒渐近曲线这一事实。例如,链表需要为每个节点分配额外的对象内存,这意味着创建节点更慢,内存访问特性也非常糟糕。
我的规则是:
ArrayList和HashSet和HashMap 开始(即不使用 LinkedList或TreeMap)。关于你的第一个问题...
List,Map和Set各有不同的用途。我建议阅读Java集合框架的文档:http://java.sun.com/docs/books/tutorial/collections/interfaces/index.html。
更具体地说:
关于你的第二个问题...
Vector和ArrayList的主要区别在于前者是同步的,后者不是同步的。您可以阅读《Java并发实践》了解更多关于同步的知识。(https://rads.stackoverflow.com/amzn/click/com/0321349601)。
Hashtable (注意T不是大写字母) 和HashMap之间的区别类似,前者是同步的,后者不是同步的。
我认为没有什么经验法则可以优先选择一种实现方式,这真的取决于您的需求。
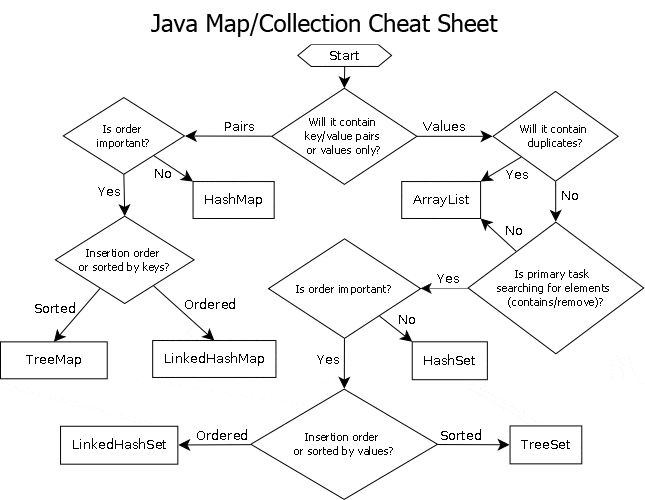
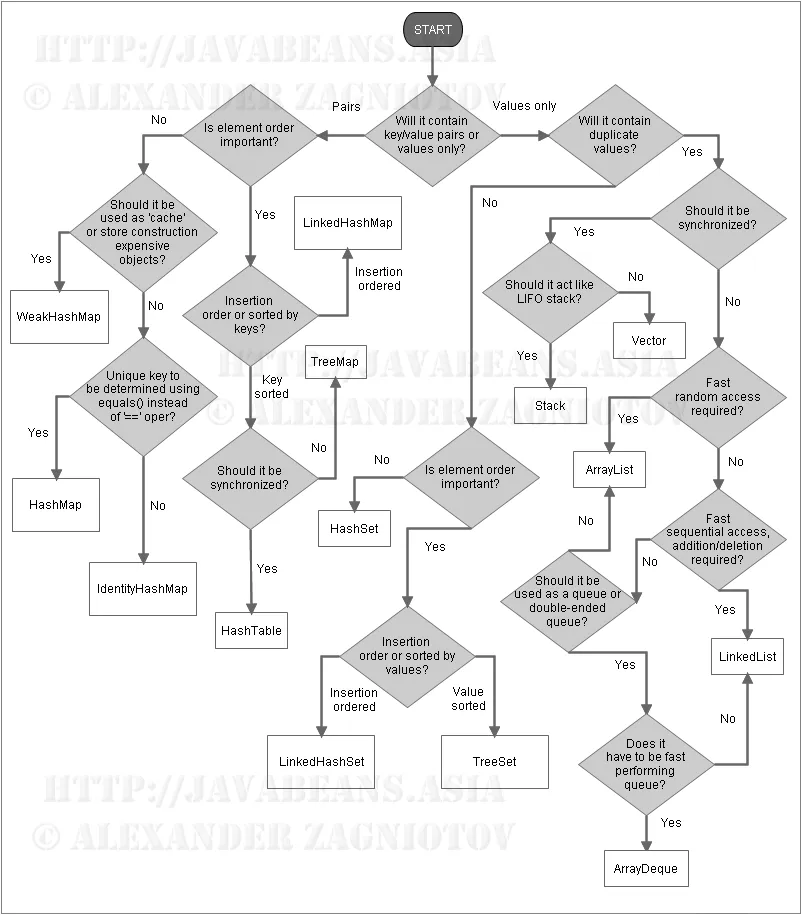
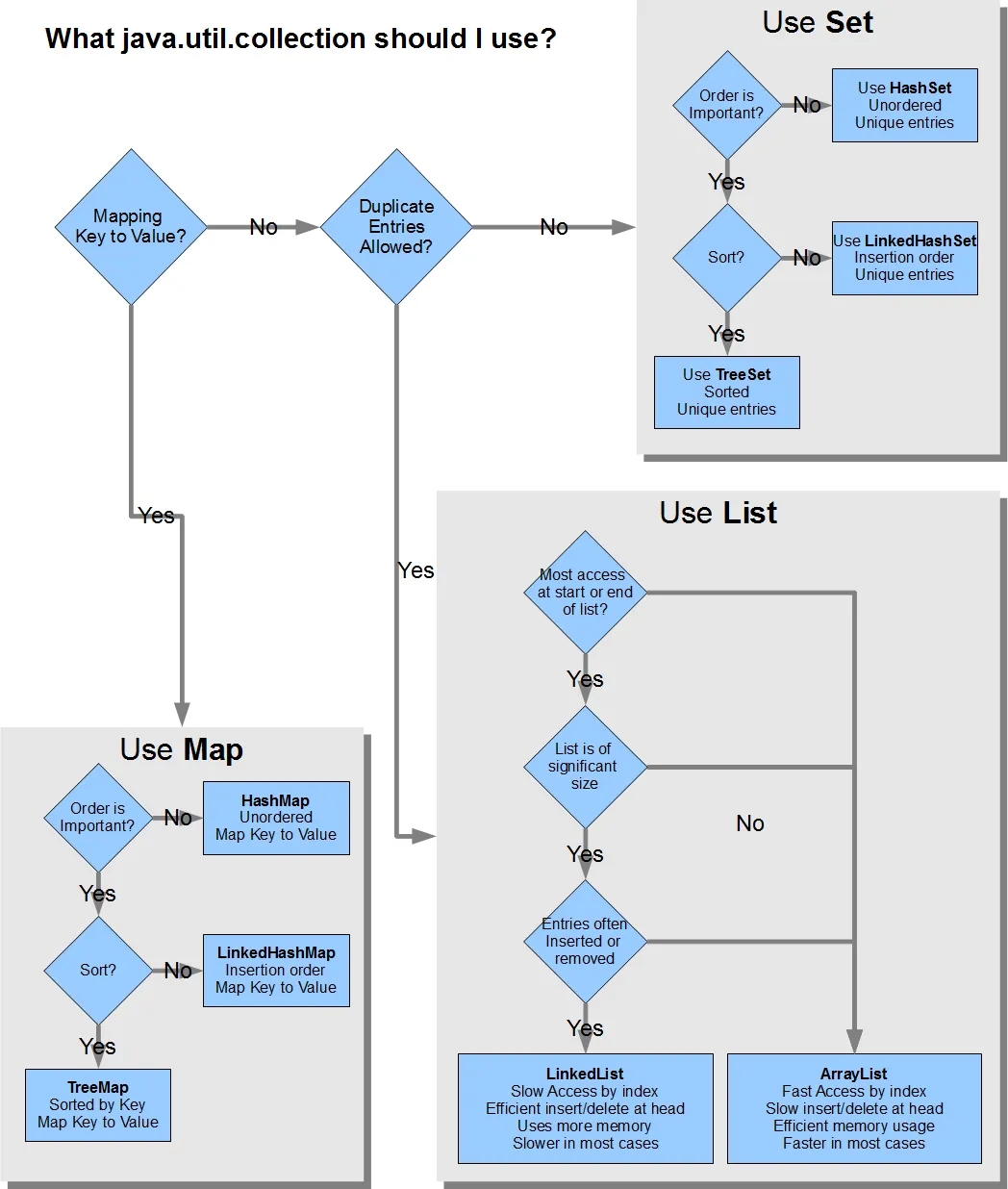 来源:https://dev59.com/3GEh5IYBdhLWcg3w0WVP#21974362
要了解更多关于Java集合的信息,请查看此文章。
来源:https://dev59.com/3GEh5IYBdhLWcg3w0WVP#21974362
要了解更多关于Java集合的信息,请查看此文章。正如其他答案所建议的那样,根据用例不同,使用正确的集合有不同的方案。我列出了一些要点:
ArrayList:
LinkedList:
HashSet:
对项目进行其他二元决策,例如“该项目是英语单词”、“该项目是否在数据库中?”、“该项目是否属于此类别?”等。
记住“您已经处理过哪些项目”,例如在进行网络爬虫时;
HashMap:
Vector和Hashtable是同步的,因此速度稍慢。如果需要同步,请使用Collections.synchronizedCollection()。有关排序集合,请查看此处。希望这可以帮助到你。