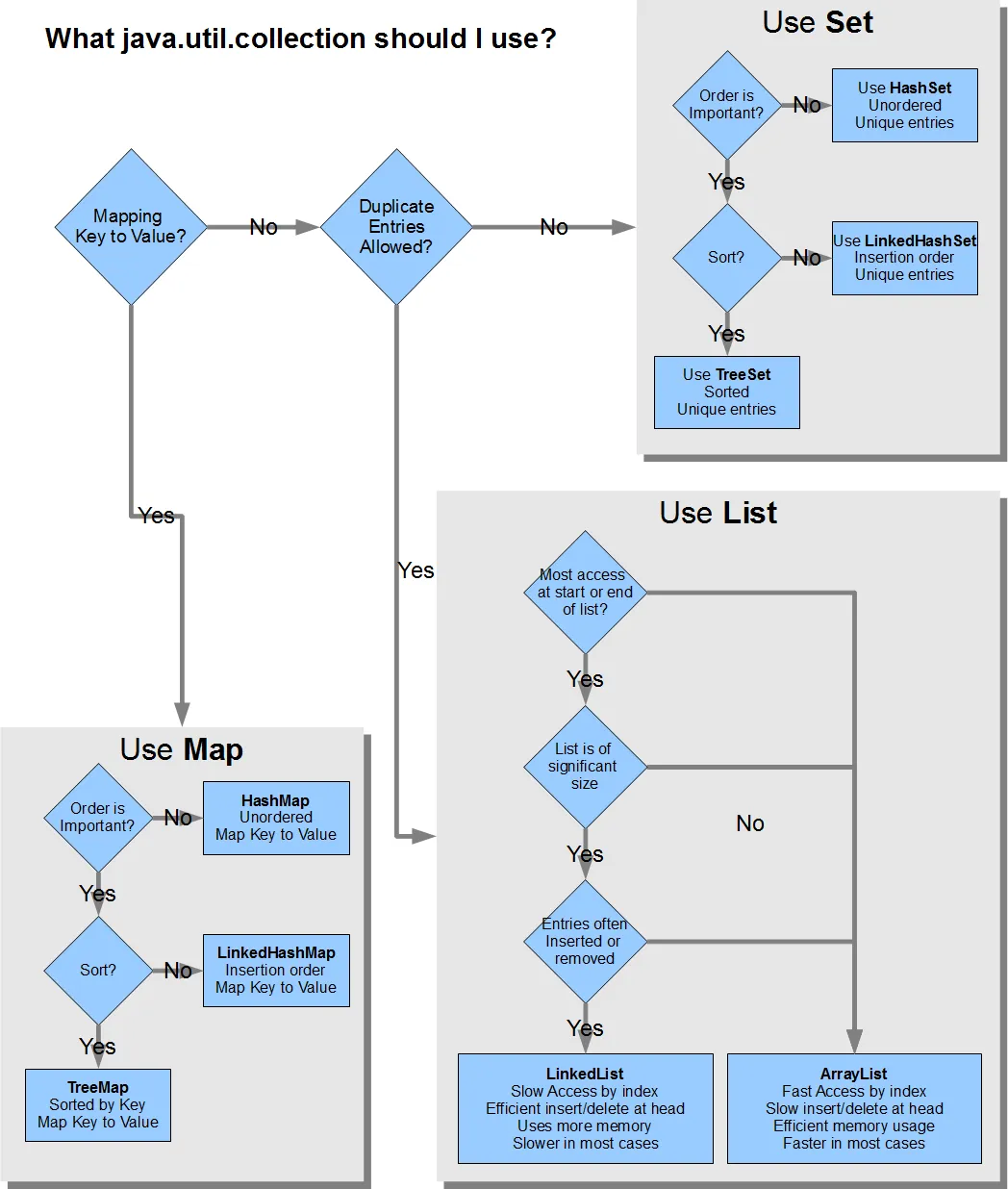
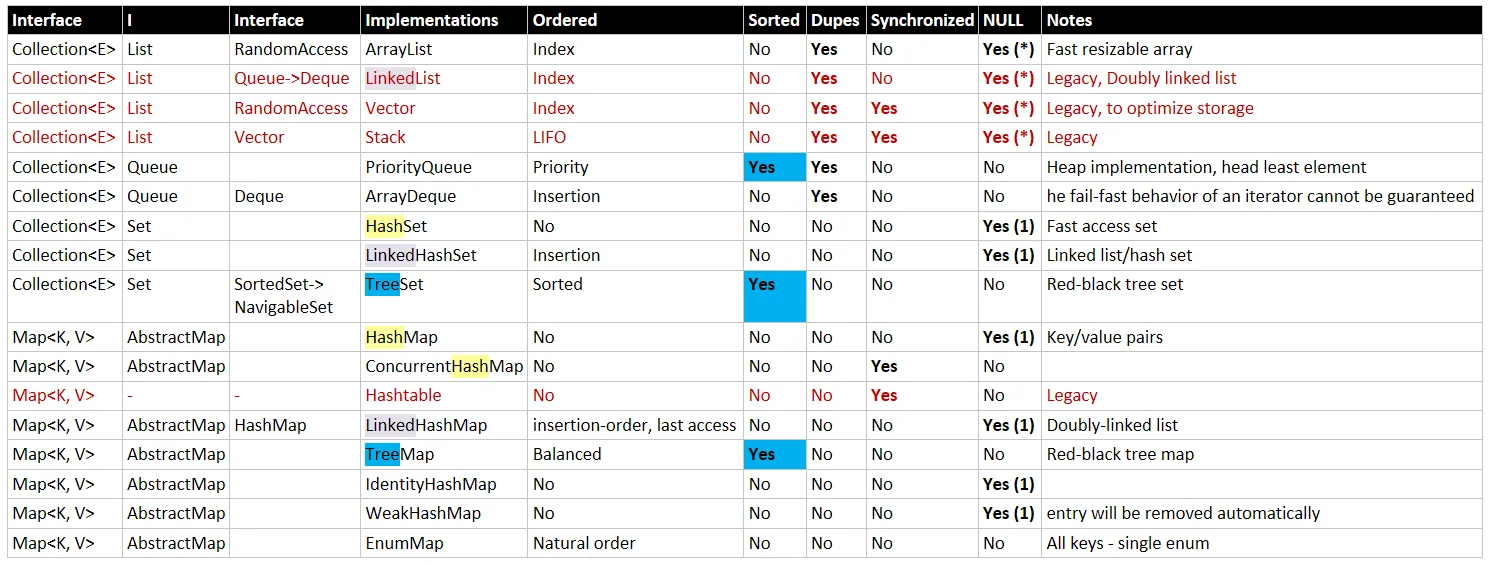
在这个问题中,如何在C++11中高效选择标准库容器?是一个很方便的流程图,用于选择C++集合。
我认为这对于不确定应该使用哪种集合的人来说是一个有用的资源,所以我尝试寻找一个类似的Java流程图,但未能找到。
有哪些资源和“备忘单”可帮助人们在编写Java代码时选择正确的集合?人们如何知道应该使用哪些List、Set和Map实现?
我认为这对于不确定应该使用哪种集合的人来说是一个有用的资源,所以我尝试寻找一个类似的Java流程图,但未能找到。
有哪些资源和“备忘单”可帮助人们在编写Java代码时选择正确的集合?人们如何知道应该使用哪些List、Set和Map实现?