我知道在一般情况下,从3D到2D的转换是不可能的,因为深度信息会丢失。
然而,我有一个固定相机,我知道它的相机矩阵。我还有一个平面标定图案,其已知尺寸 - 假设在世界坐标中它的角落点是(0,0,0) (2,0,0) (2,1,0) (0,1,0)。使用opencv,我可以估计出这个图案的姿态,给出了将物体上的点投影到图像中的像素所需的平移和旋转矩阵。
现在:这种从3D到图像的投影很容易,但反过来怎么办呢?如果我选择了一个像素,我知道它是标定图案的一部分,那么如何得到相应的3D点呢?
我可以迭代地选择一些标定图案上的随机3D点,进行2D投影,并根据误差来细化3D点。但这似乎非常可怕。
考虑到这个未知点的世界坐标大约是(x,y,0) --因为它必须位于z=0平面上--似乎应该有一些转换我可以应用,而不是做这个迭代的无聊操作。但我的数学不是很好 - 有谁能计算出这个变换并解释一下如何推导出它?
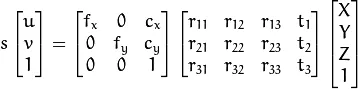{kind=link}