这是您发布的解决方案的稍微优化版本,有一些小改进。
我们检查行数是否大于列数或者反过来,然后根据情况选择将行与矩阵相乘还是矩阵与列相乘(从而进行最少的循环迭代)。
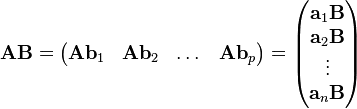
注意:即使行数少于列数,按行切片并不总是最佳策略;MATLAB数组在内存中以
列优先顺序存储,因此按列切片更有效,因为元素是连续存储的。而访问行需要通过
步长遍历元素(这不是缓存友好的——考虑
空间局部性)。
除此之外,代码应该处理双精度/单精度、实数/复数、完整/稀疏矩阵(以及不能组合的错误)。它还支持空矩阵和零维度。
function C = my_mtimes(A, B, outFcn, inFcn)
if nargin < 4, inFcn = @times; end
if nargin < 3, outFcn = @sum; end
assert(ismatrix(A) && ismatrix(B), 'Inputs must be 2D matrices.');
assert(isequal(size(A,2),size(B,1)),'Inner matrix dimensions must agree.');
assert(isa(inFcn,'function_handle') && isa(outFcn,'function_handle'), ...
'Expecting function handles.')
M = size(A,1);
N = size(B,2);
if issparse(A)
args = {'like',A};
elseif issparse(B)
args = {'like',B};
else
args = {superiorfloat(A,B)};
end
C = zeros(M,N, args{:});
if M < N
for m=1:M
C(m,:) = outFcn(bsxfun(inFcn, A(m,:)', B), 1);
end
else
for n=1:N
C(:,n) = outFcn(bsxfun(inFcn, A, B(:,n)'), 2);
end
end
end
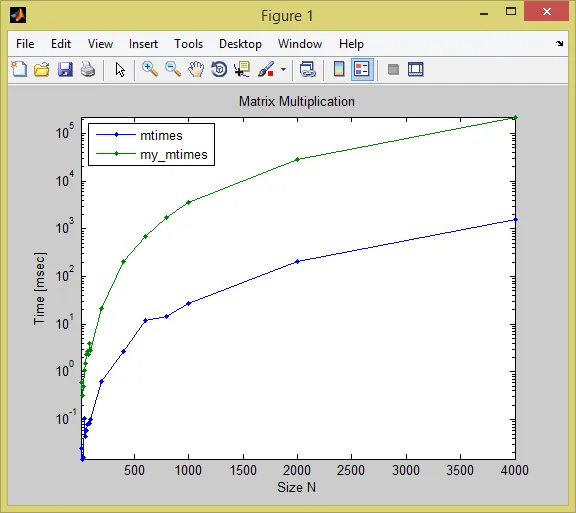
比较
该函数无疑在整个过程中速度较慢,但对于更大的尺寸,它比内置矩阵乘法慢了几个数量级:
(tic/toc times in seconds)
(tested in R2014a on Windows 8)
size mtimes my_mtimes
____ __________ _________
400 0.0026398 0.20282
600 0.012039 0.68471
800 0.014571 1.6922
1000 0.026645 3.5107
2000 0.20204 28.76
4000 1.5578 221.51
这是测试代码:
sz = [10:10:100 200:200:1000 2000 4000];
t = zeros(numel(sz),2);
for i=1:numel(sz)
n = sz(i); disp(n)
A = rand(n,n);
B = rand(n,n);
tic
C = A*B;
t(i,1) = toc;
tic
D = my_mtimes(A,B);
t(i,2) = toc;
assert(norm(C-D) < 1e-6)
clear A B C D
end
semilogy(sz, t*1000, '.-')
legend({'mtimes','my_mtimes'}, 'Interpreter','none', 'Location','NorthWest')
xlabel('Size N'), ylabel('Time [msec]'), title('Matrix Multiplication')
axis tight
额外内容
为了完整性,以下是另外两种实现广义矩阵乘法的简单方法(如果您想比较性能,请将my_mtimes函数的最后一部分替换为其中任意一种)。我甚至不会费心去发布它们的经过时间 :)
C = zeros(M,N, args{:});
for m=1:M
for n=1:N
C(m,n) = outFcn(bsxfun(inFcn, A(m,:)', B(:,n)));
end
end
另一种方法(使用三重循环):
C = zeros(M,N, args{:});
P = size(A,2);
for m=1:M
for n=1:N
for p=1:P
C(m,n) = outFcn([C(m,n) inFcn(A(m,p),B(p,n))]);
end
end
end
接下来该尝试什么?
如果您想要更多的性能,您需要转向使用C/C++ MEX文件,以减少解释型MATLAB代码的开销。您仍然可以通过从MEX文件中调用它们来利用优化的BLAS/LAPACK例程(请参阅此帖子的第二部分作为示例)。MATLAB附带Intel MKL库,当涉及到在Intel处理器上进行线性代数计算时,您无法找到更好的替代品。
其他人已经提到了File Exchange上的一些提交,这些提交将通用矩阵例程实现为MEX文件(请参见@natan的回答)。如果您将它们与优化的BLAS库链接,它们尤其有效。