这是连通组件分析,之前已经有人提出并回答了。根据那里的被接受的答案来适应您的需求,可能的解决方案非常简短:
import numpy as np
from scipy.ndimage.measurements import label
def analysis(array):
labeled, _ = label(array, np.ones((3, 3), dtype=np.int))
for i in np.arange(1, np.max(labeled)+1):
pixels = np.array(np.where(labeled == i))
x1 = np.min(pixels[1, :])
x2 = np.max(pixels[1, :])
y1 = np.min(pixels[0, :])
y2 = np.max(pixels[0, :])
print(str(i) + ' | slice: array[' + str(y1) + ':' + str(y2) + ', ' + str(x1) + ':' + str(x2) + ']')
example1 = np.array([
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 1, 1, 0],
[0, 0, 0, 0, 0, 0, 1, 1, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
]).astype(bool)
example2 = np.array([
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 1, 0, 0],
[0, 0, 0, 1, 0, 0, 1, 0, 1, 0],
[0, 0, 0, 0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 1, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 1, 0, 0, 1, 0],
[0, 0, 0, 0, 1, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
]).astype(bool)
for a in [example1, example2]:
print(a, '\n')
analysis(a)
print('\n')
这是输出的结果(不包含示例):
[[...]]
1 | slice: array[1:2, 3:5]
2 | slice: array[4:6, 6:8]
3 | slice: array[8:8, 2:2]
[[...]]
1 | slice: array[1:3, 5:8]
2 | slice: array[2:2, 3:3]
3 | slice: array[4:5, 1:1]
4 | slice: array[5:8, 3:6]
5 | slice: array[6:6, 8:8]
6 | slice: array[8:8, 8:8]
希望能帮到您!
------------------
System information
------------------
Python: 3.8.1
SciPy: 1.4.1
------------------
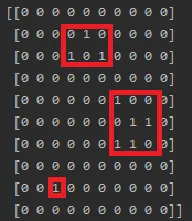 例子2:
例子2:
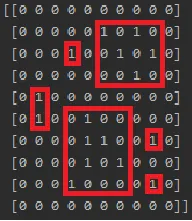 编辑!添加了新的例子并提供了正确的解决方案。对于混淆问题,我感到很抱歉。
编辑!添加了新的例子并提供了正确的解决方案。对于混淆问题,我感到很抱歉。