有没有快速的算法可以检测图像中的主要颜色?
我目前使用 k-means 和 Python 的 PIL 来查找颜色,但速度非常慢。一个 200x200 的图像需要处理 10 秒钟。我有几十万张图片。
有没有快速的算法可以检测图像中的主要颜色?
我目前使用 k-means 和 Python 的 PIL 来查找颜色,但速度非常慢。一个 200x200 的图像需要处理 10 秒钟。我有几十万张图片。
一种快速的方法是将颜色空间分成多个区间并构建直方图。这种方法快速是因为每个像素只需要做出少量的决策,整个图像只需处理一次(并且只需要处理一次直方图来查找最大值)。
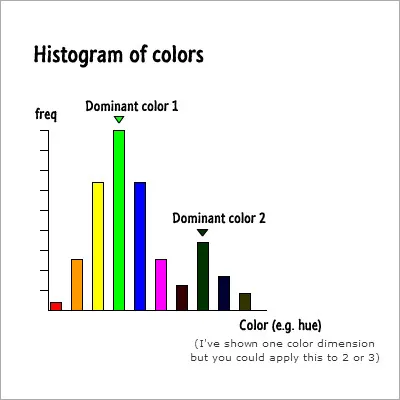
更新:下面是一个简单的图表,以帮助解释我的意思。
在x轴上是离散的颜色区间,y轴显示每个区间的值,即匹配该区间颜色范围的像素数。该图像中有两种主要颜色,分别由两个峰值表示。
稍微调整一下这段代码(我猜你可能已经看过了!),就可以将其加速到不到一秒钟。
如果将kmeans(min_diff=...)的值增加到大约10,它会产生非常相似的结果,但运行时间只有900毫秒(与min_diff=1的5000-6000毫秒相比)。
进一步减小缩略图的大小至100x100似乎也不会对结果产生太大影响,并且运行时间约为250毫秒。
这是稍微调整过的代码版本,仅将min_diff值参数化,并包含一些可怕的代码以生成带有结果/时间的HTML文件。
from collections import namedtuple
from math import sqrt
import random
try:
import Image
except ImportError:
from PIL import Image
Point = namedtuple('Point', ('coords', 'n', 'ct'))
Cluster = namedtuple('Cluster', ('points', 'center', 'n'))
def get_points(img):
points = []
w, h = img.size
for count, color in img.getcolors(w * h):
points.append(Point(color, 3, count))
return points
rtoh = lambda rgb: '#%s' % ''.join(('%02x' % p for p in rgb))
def colorz(filename, n=3, mindiff=1):
img = Image.open(filename)
img.thumbnail((200, 200))
w, h = img.size
points = get_points(img)
clusters = kmeans(points, n, mindiff)
rgbs = [map(int, c.center.coords) for c in clusters]
return map(rtoh, rgbs)
def euclidean(p1, p2):
return sqrt(sum([
(p1.coords[i] - p2.coords[i]) ** 2 for i in range(p1.n)
]))
def calculate_center(points, n):
vals = [0.0 for i in range(n)]
plen = 0
for p in points:
plen += p.ct
for i in range(n):
vals[i] += (p.coords[i] * p.ct)
return Point([(v / plen) for v in vals], n, 1)
def kmeans(points, k, min_diff):
clusters = [Cluster([p], p, p.n) for p in random.sample(points, k)]
while 1:
plists = [[] for i in range(k)]
for p in points:
smallest_distance = float('Inf')
for i in range(k):
distance = euclidean(p, clusters[i].center)
if distance < smallest_distance:
smallest_distance = distance
idx = i
plists[idx].append(p)
diff = 0
for i in range(k):
old = clusters[i]
center = calculate_center(plists[i], old.n)
new = Cluster(plists[i], center, old.n)
clusters[i] = new
diff = max(diff, euclidean(old.center, new.center))
if diff < min_diff:
break
return clusters
if __name__ == '__main__':
import sys
import time
for x in range(1, 11):
sys.stderr.write("mindiff %s\n" % (x))
start = time.time()
fname = "akira_940x700.png"
col = colorz(fname, 3, x)
print "<h1>%s</h1>" % x
print "<img src='%s'>" % (fname)
print "<br>"
for a in col:
print "<div style='background-color: %s; width:20px; height:20px'> </div>" % (a)
print "<br>Took %.02fms<br> % ((time.time()-start)*1000)
K-means 是这项任务的好选择,因为您事先知道主要颜色的数量。您需要优化 K-means。我认为您可以缩小图像尺寸,将其缩小为 100x100 像素左右。找到您的算法在可接受速度下工作的尺寸。另一个选项是在 K-means 聚类之前使用降维。
尝试找到快速的 K-means 实现。用 Python 编写此类东西是对 Python 的滥用。它不应该被用于这种情况。