我第一次使用Python Pandas。我有5分钟滞后的csv格式交通数据:
...
2015-01-04 08:29:05,271238
2015-01-04 08:34:05,329285
2015-01-04 08:39:05,-1
2015-01-04 08:44:05,260260
2015-01-04 08:49:05,263711
...
存在几个问题:
- 某些时间戳存在缺失数据(-1)
- 存在缺失条目(也有两三个连续小时的情况)
- 观测频率不完全是5分钟,实际上偶尔会丢失几秒钟
我希望获得一个规则的时间序列,每5分钟一个条目(确切地说没有缺失值)。我已经成功地使用以下代码对时间序列进行了插值以近似-1值:
ts = pd.TimeSeries(values, index=timestamps)
ts.interpolate(method='cubic', downcast='infer')
我应该如何同时插值和正则化观测频率?感谢大家的帮助。
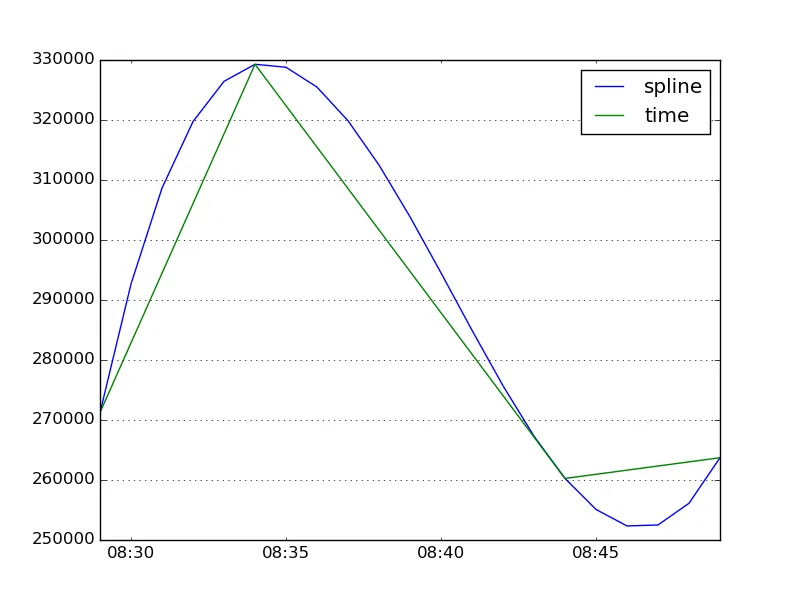
ts.interpolate(method='time').plot()这一行以及与labels中的time相关联的内容即可。然后上述代码将仅使用三阶样条插值对数据进行插值。 - unutbuhow='mean'告诉resample如果多行数据落在同一时间段内(在本例中,T表示每个时间段的频率为 1 分钟),如何聚合这些值。 - unutburesample对Series进行重采样,而是使用reindex添加带有NaN值的新行。然后调用Series.interpolate(method='time')将使用插值方法填充缺失值。 - unutbucombine_first。(想一想,combine_first可能是更好的解决方案,因为如果你使用reindex,你将不得不将旧索引与新索引合并...) - unutbu