我希望从扫描表格中提取信息并将其存储为csv。目前,我的表格提取算法执行以下步骤:
这是一个样本图像,其中我的算法失败了。
- 应用倾斜校正
- 使用高斯滤波器进行降噪。
- 使用Otsu阈值进行二值化
- 进行形态学开运算。
- Canny边缘检测
- 进行霍夫变换以获取表格线。
- 删除重复线(在10个像素范围内相同的线)
- 使用线的斜率过滤水平和垂直线(水平线的斜率应小于+/-5度,垂直线的法线应小于+/-5度)。
这是一个样本图像,其中我的算法失败了。
2.大津阈值处理
3.形态学开运算
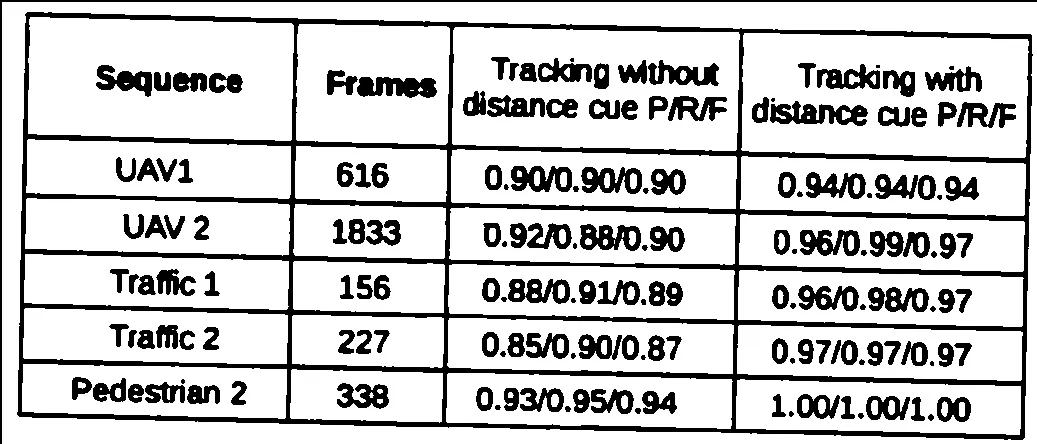
4. Canny边缘检测
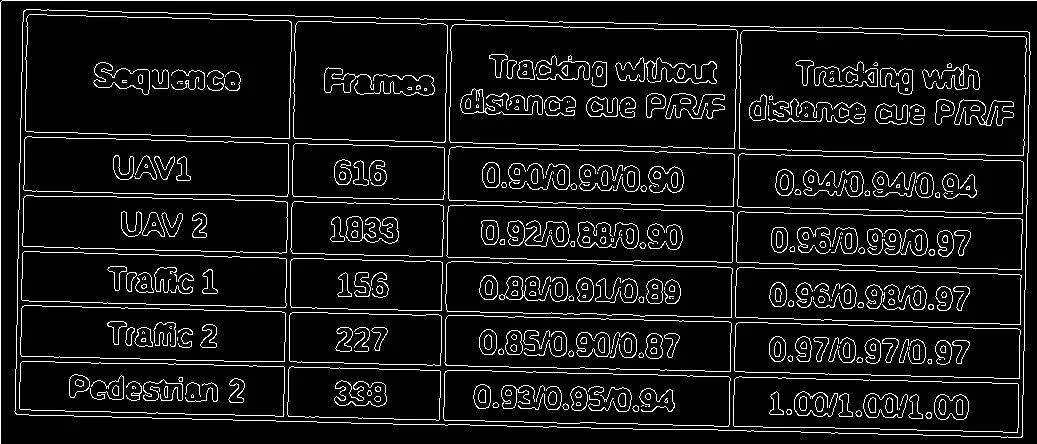
5条过滤后的行,正如您所看到的,这些行明显未被正确识别。
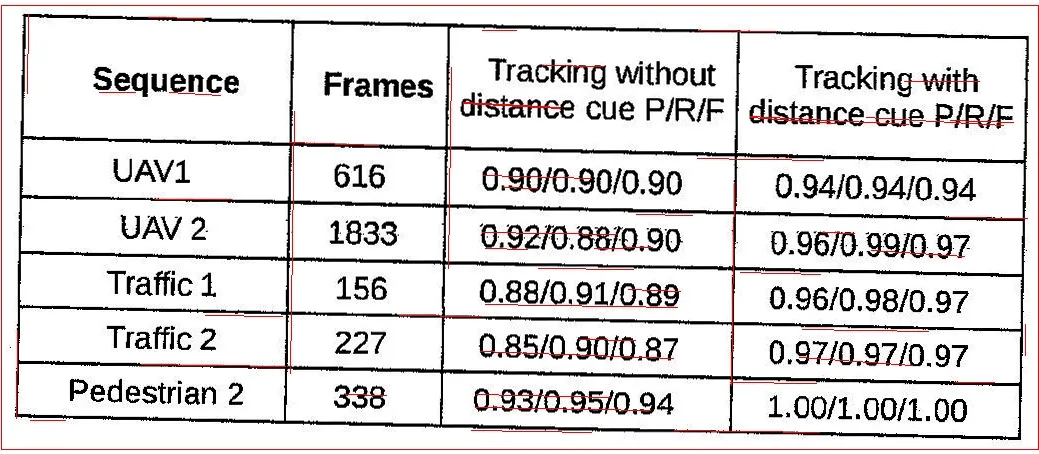
请问有没有更好的方法可以从这种低质量扫描件中提取水平和垂直线条。
谢谢提前!