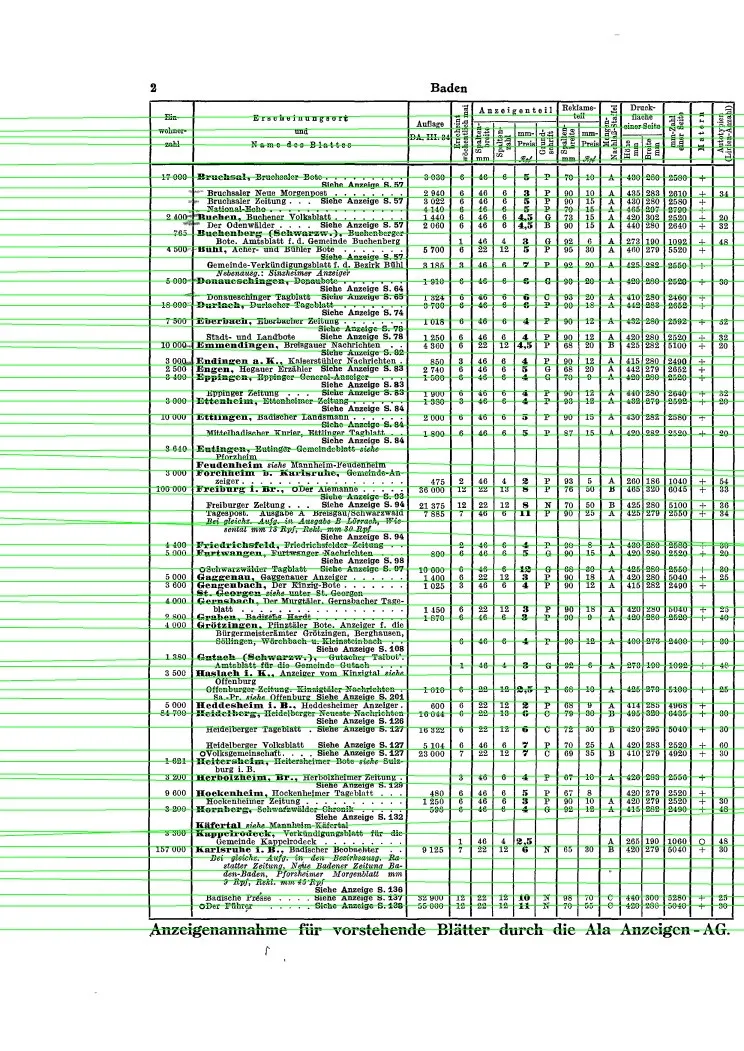
我写了一些代码来估计页面上印刷字母的水平线。我猜垂直线也可以这样做。下面的代码遵循一些常见的假设,在此提供一些伪代码风格的基本步骤:
这是完整的代码:
import cv2
import numpy as np
from scipy import stats
def resizeImageByPercentage(img,scalePercent = 60):
width = int(img.shape[1] * scalePercent / 100)
height = int(img.shape[0] * scalePercent / 100)
dim = (width, height)
return cv2.resize(img, dim, interpolation = cv2.INTER_AREA)
def calcAverageContourWithAndHeigh(contourList):
hs = list()
ws = list()
for cnt in contourList:
(x, y, w, h) = cv2.boundingRect(cnt)
ws.append(w)
hs.append(h)
return np.mean(ws),np.mean(hs)
def calcAverageContourArea(contourList):
areaList = list()
for cnt in contourList:
a = cv2.minAreaRect(cnt)
areaList.append(a[2])
return np.mean(areaList)
def calcCentroid(contour):
houghMoments = cv2.moments(contour)
if houghMoments["m00"] != 0:
cX = int(houghMoments["m10"] / houghMoments["m00"])
cY = int(houghMoments["m01"] / houghMoments["m00"])
else:
cX, cY = -1, -1
return cX,cY
def getCentroidWhenSizeInRange(contourList,letterSizeWidth,letterSizeHigh,deltaOffset,minLetterArea=10.0):
centroidList=list()
for cnt in contourList:
(x, y, w, h) = cv2.boundingRect(cnt)
area = cv2.minAreaRect(cnt)
diffW = abs(w-letterSizeWidth)
diffH = abs(h-letterSizeHigh)
if diffW < deltaOffset and diffH < deltaOffset:
if area[2] > minLetterArea:
cX,cY = calcCentroid(cnt)
if cX!=-1 and cY!=-1:
centroidList.append((cX,cY))
return centroidList
DEBUGMODE = True
img = cv2.imread('pdftabextract/examples/catalogue_30s/data/ALA1934_RR-excerpt.pdf-2_1.png')
imgHeigh, imgWidth, imgChannelAmount = img.shape
if DEBUGMODE:
cv2.imwrite("img00original.jpg",resizeImageByPercentage(img,30))
cv2.imshow("original",img)
imgGrey = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
imgGaussianBlur = cv2.GaussianBlur(imgGrey,(5,5),0)
_, imgBinThres = cv2.threshold(imgGaussianBlur, 130, 255, cv2.THRESH_BINARY)
contours, _ = cv2.findContours(imgBinThres, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
averageLetterWidth, averageLetterHigh = calcAverageContourWithAndHeigh(contours)
threshold1AllowedLetterSizeOffset = averageLetterHigh * 2
averageContourAreaSizeOfMinRect = calcAverageContourArea(contours)
threshHold2MinArea = 4 * averageContourAreaSizeOfMinRect / 5
print("mean letter Width: ", averageLetterWidth)
print("mean letter High: ", averageLetterHigh)
print("threshold 1 tolerance: ", threshold1AllowedLetterSizeOffset)
print("mean letter area ", averageContourAreaSizeOfMinRect)
print("thresold 2 min letter area ", threshHold2MinArea)
centroidList = getCentroidWhenSizeInRange(contours,averageLetterWidth,averageLetterHigh,threshold1AllowedLetterSizeOffset,threshHold2MinArea)
if DEBUGMODE:
imgFilteredCenter = img.copy()
for cX,cY in centroidList:
cv2.circle(imgFilteredCenter, (cX, cY), 5, (0, 0, 255), -1)
cv2.imwrite("img01letterCenters.jpg",resizeImageByPercentage(imgFilteredCenter,30))
cv2.imshow("letterCenters",imgFilteredCenter)
amountPixelFreeSpace = averageLetterHigh
estimatedBinWidth = round( averageLetterHigh + amountPixelFreeSpace)
binCollection = dict()
for i in range(0,imgHeigh,estimatedBinWidth):
listCenterPointsInBin = list()
yMin = i
yMax = i + estimatedBinWidth
for cX,cY in centroidList:
if yMin < cY < yMax:
listCenterPointsInBin.append((cX,cY))
binCollection[i] = listCenterPointsInBin
mList = list()
nList = list()
nListRelative = list()
minAmountRegressionElements = 12
for startYOfBin, values in binCollection.items():
xValues = []
yValues = []
for x,y in values:
xValues.append(x)
yValues.append(y)
if len(xValues) >= minAmountRegressionElements :
slope, intercept, r, p, std_err = stats.linregress(xValues, yValues)
mList.append(slope)
nList.append(intercept)
nRelativeToBinStart = intercept - startYOfBin
nListRelative.append(nRelativeToBinStart)
if DEBUGMODE:
imgLines = img.copy()
colorOfLine = (0, 255, 0)
for i in range(0,len(mList)):
slope = mList[i]
intercept = nList[i]
startPoint = (0, int( intercept))
endPointY = int( (slope * imgWidth + intercept) )
if endPointY < 0:
endPointY = 0
endPoint = (imgHeigh,endPointY)
cv2.line(imgLines, startPoint, endPoint, colorOfLine, 2)
cv2.imwrite("img02lines.jpg",resizeImageByPercentage(imgLines,30))
cv2.imshow("linesOfLetters ",imgLines)
meanIntercept = np.mean(nListRelative)
meanSlope = np.mean(mList)
print("meanIntercept :", meanIntercept)
print("meanSlope ", meanSlope)
if DEBUGMODE:
cv2.waitKey(0)
原始图片:
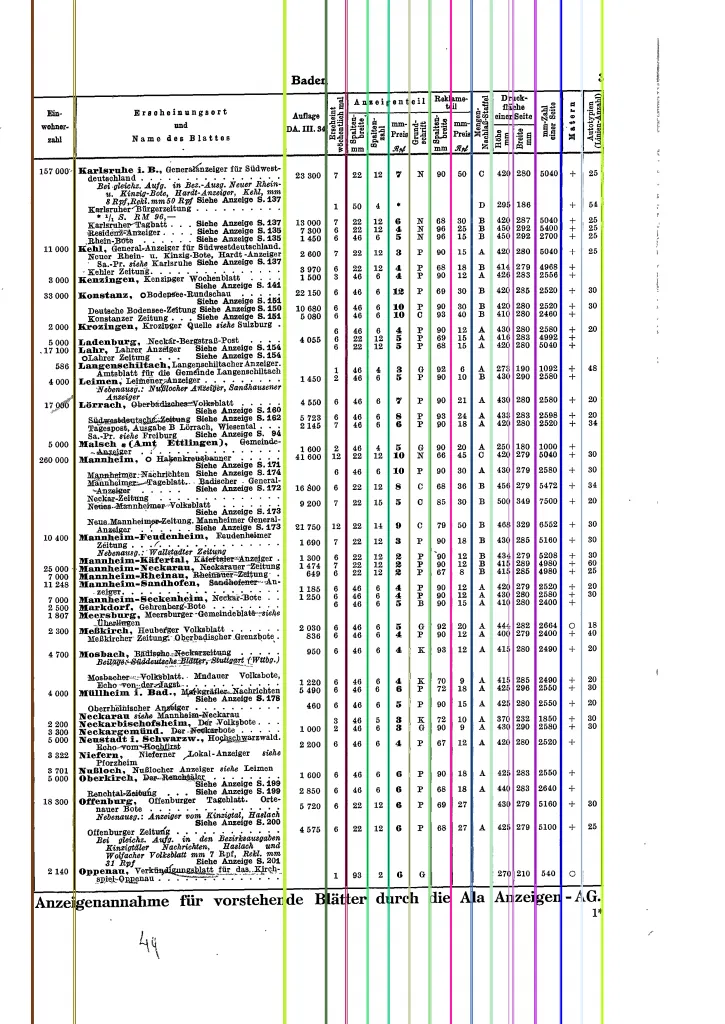
 字母中心点:
字母中心点:
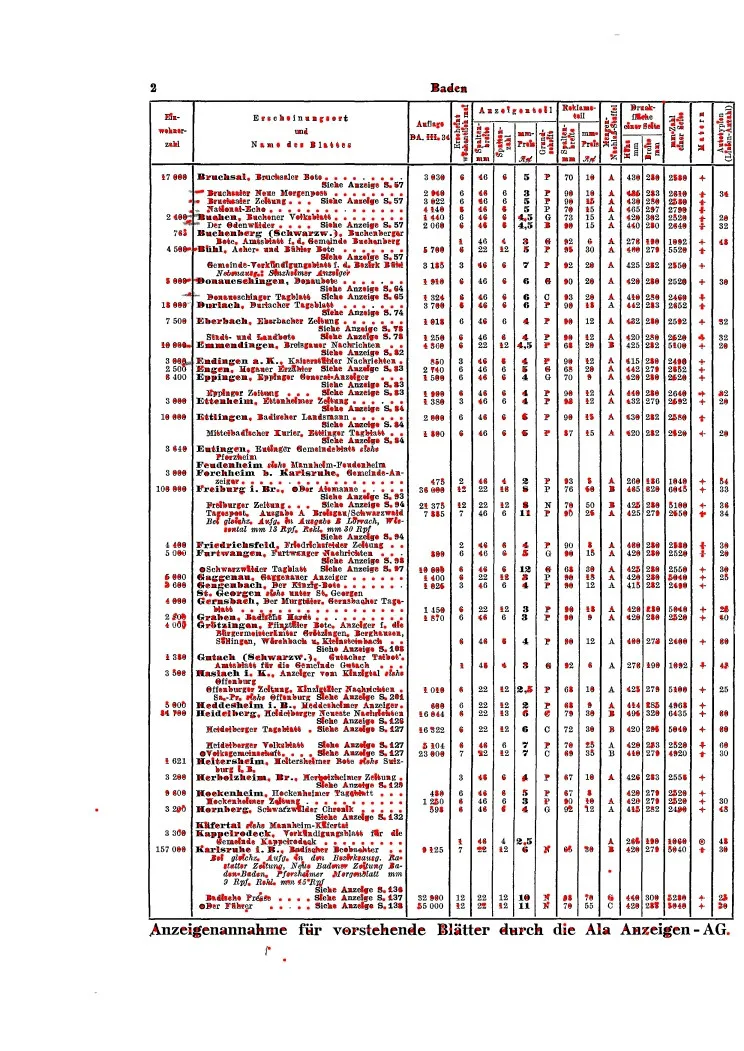 线条:
线条: