我有一个带有多级索引的DataFrame,想要使用字典来添加新行。
假设DataFrame中的每一行都是一个城市。列包含“距离”和“车辆”。每个单元格将是选择该车辆行驶该距离的人口百分比。
我正在构建这样的索引:
index_tuples=[]
for distance in ["near", "far"]:
for vehicle in ["bike", "car"]:
index_tuples.append([distance, vehicle])
index = pd.MultiIndex.from_tuples(index_tuples, names=["distance", "vehicle"])
然后我创建一个数据框:
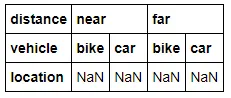
dataframe = pd.DataFrame(index=["city"], columns = index)
数据框的结构看起来不错。虽然pandas已经添加了NaN作为默认值?
my_home_city = {"near":{"bike":1, "car":0},"far":{"bike":0, "car":1}}
dataframe["my_home_city"] = my_home_city
但是这个操作失败了:
ValueError: 值的长度与索引的长度不匹配
这里是完整的error message(pastebin)
更新:
感谢所有好的回答。恐怕我在示例中过于简化了问题。实际上,我的索引嵌套了3个级别(并且可能会变得更多)。
因此,我接受了将字典转换为元组列表的通用答案。这可能不像其他方法那样干净,但适用于任何多重索引设置。
{('near', 'bike'): 1, ('near', 'car'): 0 ...}。 - Paul Hpandas.MultiIndex.from_product。 - Paul H