一台机器生成故障代码,这些代码以pandas数据框的形式提供。
id用于标识该机器,code则是故障代码。df = pd.DataFrame({
"id": [1,1,1,1,1,2,2,2,2,3,3,3,3,3,3,4],
"code": [1,2,5,8,9,2,3,5,6,1,2,3,4,5,6,7],
})
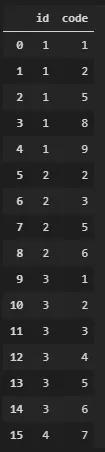
示例:机器1生成了5个代码: 1、2、5、8和9。
我希望找出所有机器中最常见的代码组合。对于这个示例,结果可能是:[2](3次), [2,5](3次), [3,5](2次)等。
如何实现这一点?由于数据很多,因此我正在寻找一种高效的解决方案。
以下是另外两种表示数据的方式(以防这有助于计算):
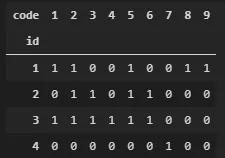
pd.crosstab(df.id, df.code)
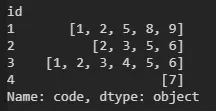
df.groupby("id")["code"].apply(list)
[2,5]和[5,2]不同吗? - sophros[2,5]等同于[5,2]。 - Julian