我有一个如下所示的列表。a=[1936,2401,2916,4761,9216,9216,9604,9801] 我想要获取具有更多重复项的值。在这里是 '9216',我该如何获取这个值?谢谢
如何在Python中从列表中获取最常见的元素
7
- Dimuth Ruwantha
4个回答
15
你可以使用
collections.Counter来完成这个任务:from collections import Counter
a = [1936, 2401, 2916, 4761, 9216, 9216, 9604, 9801]
c = Counter(a)
print(c.most_common(1)) # the one most common element... 2 would mean the 2 most common
[(9216, 2)] # a set containing the element, and it's count in 'a'
来自文档:
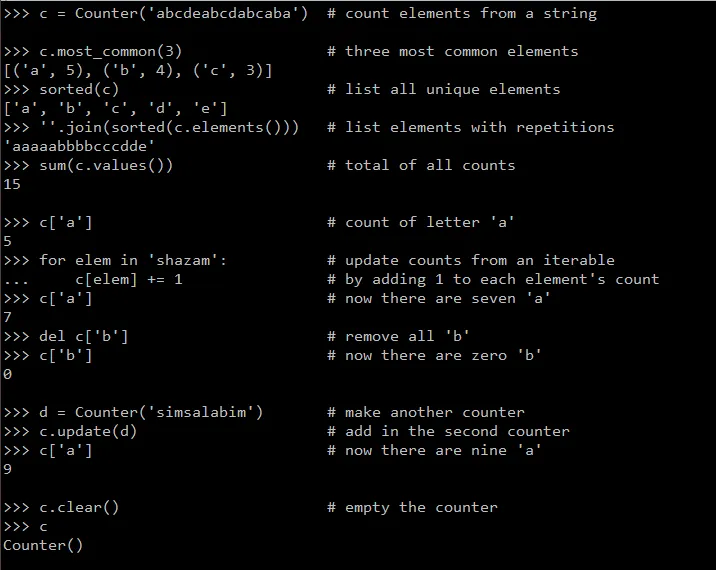
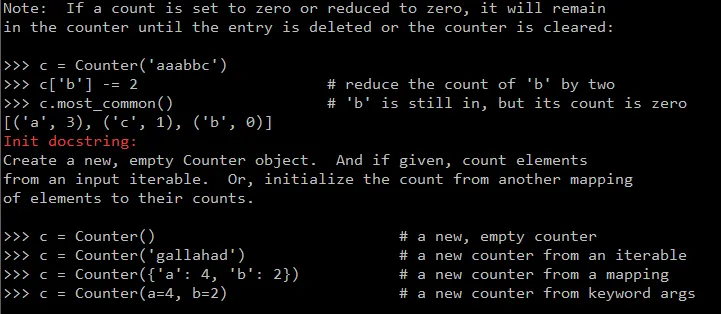
- Totem
3
这有两种标准库方法可以实现:
statistics.mode:
请参见文档。from statistics import mode
most_common = mode([3, 2, 2, 2, 1]) # 2
most_common = mode([3, 2]) # StatisticsError: no unique mode
collections.Counter.most_common:
from collections import Counter
most_common, count = Counter([3, 2, 2, 2, 1]).most_common(1)[0] # 2, 3
most_common, count = Counter([3, 2]).most_common(1)[0] # 3, 1
两者在性能方面完全相同,但第一个会在没有唯一最常见元素时引发异常,而第二个也会返回频率。
- Matthew D. Scholefield
1
这是另一个不使用计数器的例子。
a=[1936,2401,2916,4761,9216,9216,9604,9801]
frequency = {}
for element in a:
frequency[element] = frequency.get(element, 0) + 1
# create a list of keys and sort the list
# all words are lower case already
keyList = frequency.keys()
keyList.sort()
print "Frequency of each word in the word list (sorted):"
for keyElement in keyList:
print "%-10s %d" % (keyElement, frequency[keyElement])
- Stefan Gruenwald
0
https://docs.python.org/2.7/library/collections.html#counter
从 collections 模块导入 Counter Counter(a).most_common(1)
- gyu-don
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接