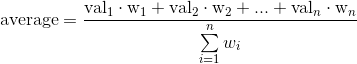我有一个数组:
In [37]: bias_2e13 # our array
Out[37]:
[1.7277990734072355,
1.9718263893212737,
2.469657573252167,
2.869022991373125,
3.314720313010104,
4.232269039271717]
每个数组值的误差为:
In [38]: bias_error_2e13 # the error on each value
Out[38]:
array([ 0.13271387, 0.06842465, 0.06937965, 0.23886647, 0.30458249,
0.57906816])
现在,我将每个值上的误差除以2:
In [39]: error_half # error divided by 2
Out[39]:
array([ 0.06635694, 0.03421232, 0.03468982, 0.11943323, 0.15229124,
0.28953408])
现在我使用numpy.average来计算数组的平均值,但是使用errors作为weights。
首先,我将完整的误差应用于数值,然后我将误差减半,即将误差除以2。
In [40]: test = np.average(bias_2e13,weights=bias_error_2e13)
In [41]: test_2 = np.average(bias_2e13,weights=error_half)
当一个数组的错误率是另一个数组的一半时,两个平均数为何给出相同的结果?
In [42]: test
Out[42]: 3.3604746813456936
In [43]: test_2
Out[43]: 3.3604746813456936