我将尝试使用以下数据框进行实验。
设置
import pandas as pd
import numpy as np
from string import uppercase
def generic_portfolio_df(start, end, freq, num_port, num_sec, seed=314):
np.random.seed(seed)
portfolios = pd.Index(['Portfolio {}'.format(i) for i in uppercase[:num_port]],
name='Portfolio')
securities = ['s{:02d}'.format(i) for i in range(num_sec)]
dates = pd.date_range(start, end, freq=freq)
return pd.DataFrame(np.random.rand(len(dates) * num_sec, num_port),
index=pd.MultiIndex.from_product([dates, securities],
names=['Date', 'Id']),
columns=portfolios
).groupby(level=0).apply(lambda x: x / x.sum())
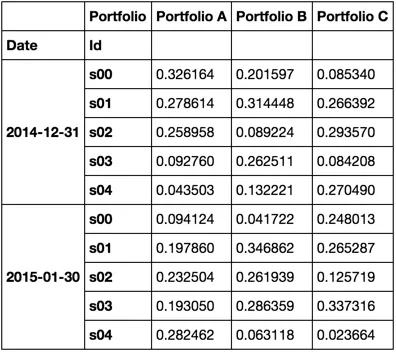
df = generic_portfolio_df('2014-12-31', '2015-05-30', 'BM', 3, 5)
df.head(10)
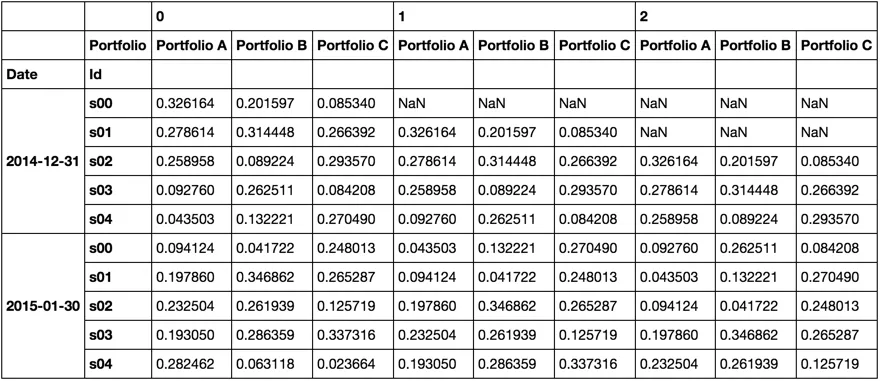
我现在将介绍一个函数来滚动多行并将它们连接成一个单独的数据框,其中我将添加一个顶级到列索引,指示滚动中的位置。
解决方案步骤1
def rolled(df, n):
k = range(df.columns.nlevels)
_k = [i - len(k) for i in k]
myroll = pd.concat([df.shift(i).stack(level=k) for i in range(n)],
axis=1, keys=range(n)).unstack(level=_k)
return [(i, row.unstack(0)) for i, row in myroll.iterrows()]
< p > 虽然它藏在函数中,但 < code > myroll 看起来像这样
现在我们可以像使用迭代器一样使用它。
解决方案步骤二
for i, roll in rolled(df.head(5), 3):
print roll
print
0 1 2
Portfolio
Portfolio A 0.326164 NaN NaN
Portfolio B 0.201597 NaN NaN
Portfolio C 0.085340 NaN NaN
0 1 2
Portfolio
Portfolio A 0.278614 0.326164 NaN
Portfolio B 0.314448 0.201597 NaN
Portfolio C 0.266392 0.085340 NaN
0 1 2
Portfolio
Portfolio A 0.258958 0.278614 0.326164
Portfolio B 0.089224 0.314448 0.201597
Portfolio C 0.293570 0.266392 0.085340
0 1 2
Portfolio
Portfolio A 0.092760 0.258958 0.278614
Portfolio B 0.262511 0.089224 0.314448
Portfolio C 0.084208 0.293570 0.266392
0 1 2
Portfolio
Portfolio A 0.043503 0.092760 0.258958
Portfolio B 0.132221 0.262511 0.089224
Portfolio C 0.270490 0.084208 0.293570