考虑以下两个含有三个字典和三个空数据框的列表。
然而,当尝试在循环外检索df的第1个实例时,它仍然为空。
当在for循环中打印df时,我们可以看到数据被正确地追加了。 如何使循环能够在循环外打印具有更改的3个dfs?
dict0={'actual': {'2013-02-20 13:30:00': 0.93}}
dict1={'actual': {'2013-02-20 13:30:00': 0.85}}
dict2={'actual': {'2013-02-20 13:30:00': 0.98}}
dicts=[dict0, dict1, dict2]
df0=pd.DataFrame()
df1=pd.DataFrame()
df2=pd.DataFrame()
dfs=[df0, df1, df2]
我希望在循环中使用以下代码对3个数据框进行递归修改:
for df, dikt in zip(dfs, dicts):
df = df.from_dict(dikt, orient='columns', dtype=None)
然而,当尝试在循环外检索df的第1个实例时,它仍然为空。
print (df0)
将返回
Empty DataFrame
Columns: []
Index: []
当在for循环中打印df时,我们可以看到数据被正确地追加了。 如何使循环能够在循环外打印具有更改的3个dfs?
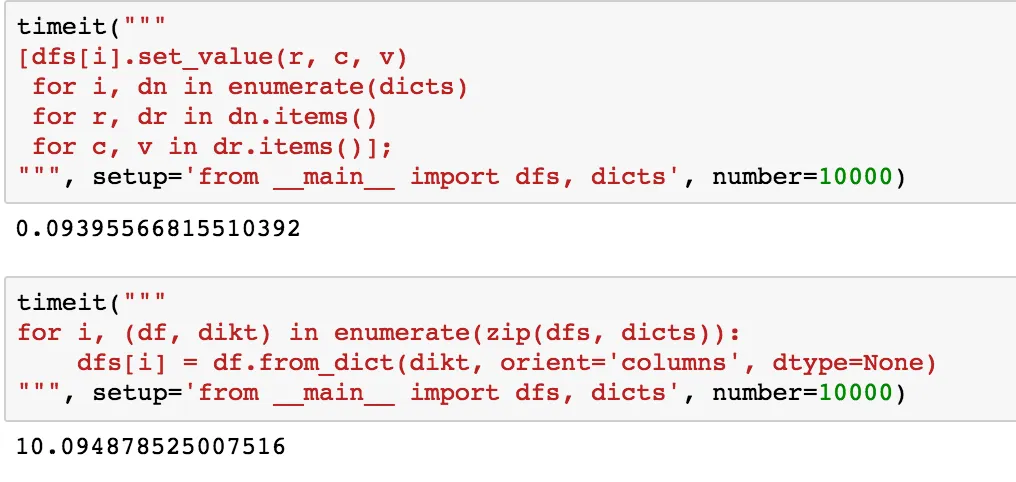
set_value。使用set_value或pd.DataFrame.at或pd.DataFrame.loc是我能想到的唯一选项来原地编辑数据框。为了获取那些行、列、值组合,我必须进行迭代。我本可以使用数据框构造函数来迭代,但这是不必要的。 - piRSquared