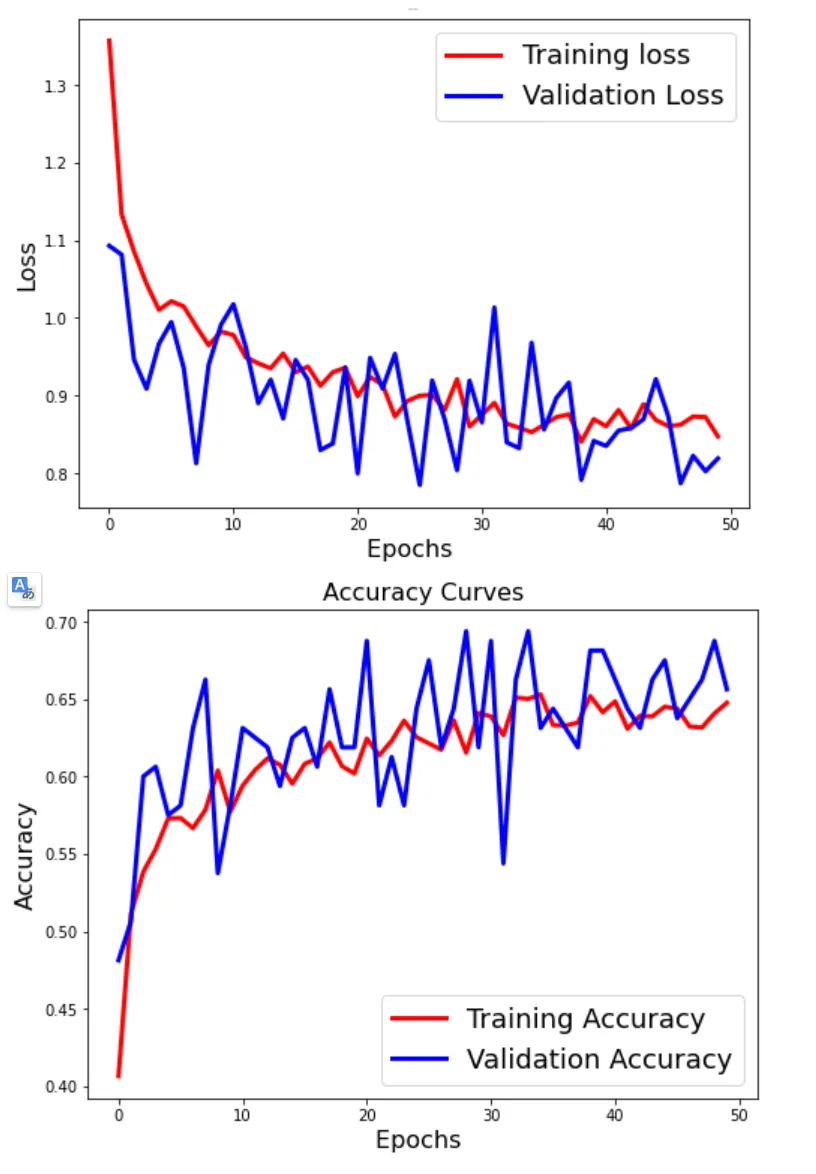
我建立了一个 CNN 模型,用于将面部情绪分为开心、悲伤、精力充沛和中性表情。我使用了 Vgg16 预训练模型,并冻结了所有层。在训练 50 个 epoch 后,我的模型测试准确率为 0.65,验证损失约为 0.8。
我的训练数据文件夹有 16000(4x4000)张图片,验证数据文件夹有 2000(4x500)张图片,测试数据文件夹有 4000(4x1000)张 RGB 图片。
1)您对提高模型准确度有什么建议?
2)我尝试使用我的模型进行一些预测,但预测的类总是相同的。这可能是什么问题造成的?
我尝试过什么?
- 添加了一个 dropout 层(0.5)
- 在最后一层之前添加了 Dense(256,relu)
- 打乱了训练和验证数据。
- 将学习率降低到 1e-5
但是我无法提高验证和测试准确度。
我的代码:
train_src = "/content/drive/MyDrive/Affectnet/train_class/"
val_src = "/content/drive/MyDrive/Affectnet/val_class/"
test_src="/content/drive/MyDrive/Affectnet/test_classs/"
train_datagen = tensorflow.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
)
train_generator = train_datagen.flow_from_directory(
train_src,
target_size=(224,224 ),
batch_size=32,
class_mode='categorical',
shuffle=True
)
validation_datagen = tensorflow.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255
)
validation_generator = validation_datagen.flow_from_directory(
val_src,
target_size=(224, 224),
batch_size=32,
class_mode='categorical',
shuffle=True
)
conv_base = tensorflow.keras.applications.VGG16(weights='imagenet',
include_top=False,
input_shape=(224, 224, 3)
)
for layer in conv_base.layers:
layer.trainable = False
model = tensorflow.keras.models.Sequential()
# VGG16 is added as convolutional layer.
model.add(conv_base)
# Layers are converted from matrices to a vector.
model.add(tensorflow.keras.layers.Flatten())
# Our neural layer is added.
model.add(tensorflow.keras.layers.Dropout(0.5))
model.add(tensorflow.keras.layers.Dense(256, activation='relu'))
model.add(tensorflow.keras.layers.Dense(4, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=tensorflow.keras.optimizers.Adam(lr=1e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
epochs=50,
steps_per_epoch=100,
validation_data=validation_generator,
validation_steps=5,
workers=8
)
{kind=link}