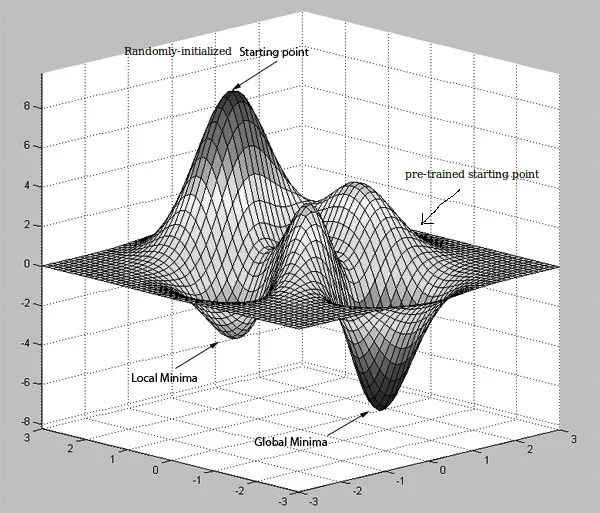
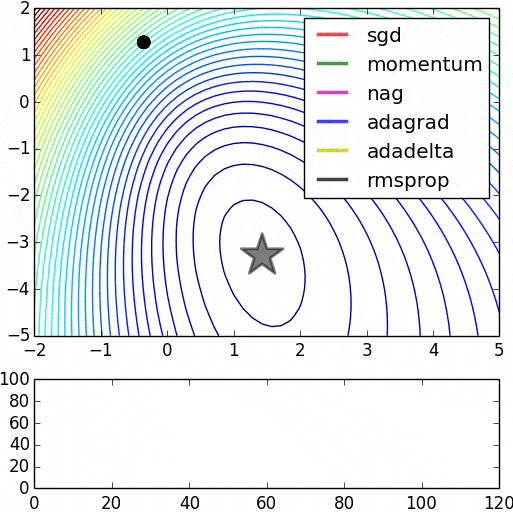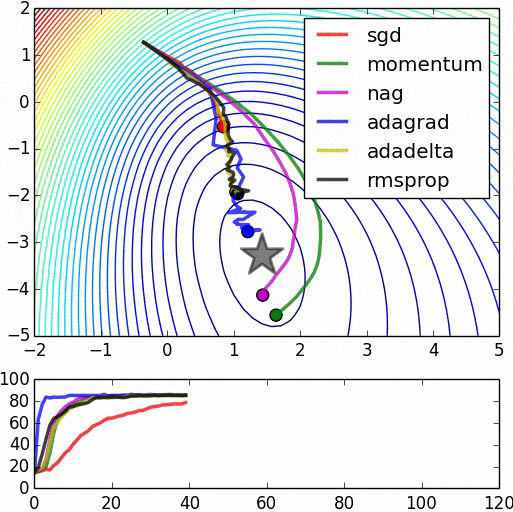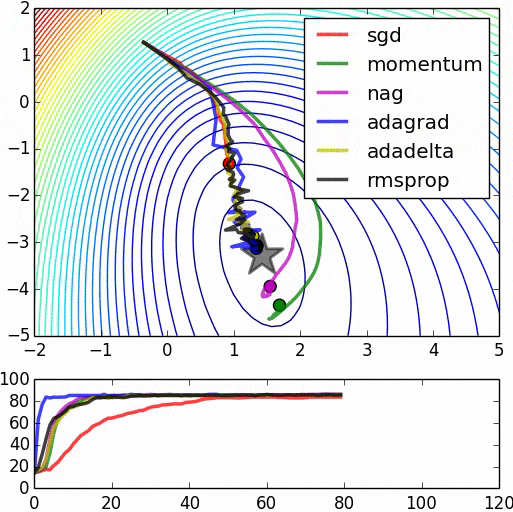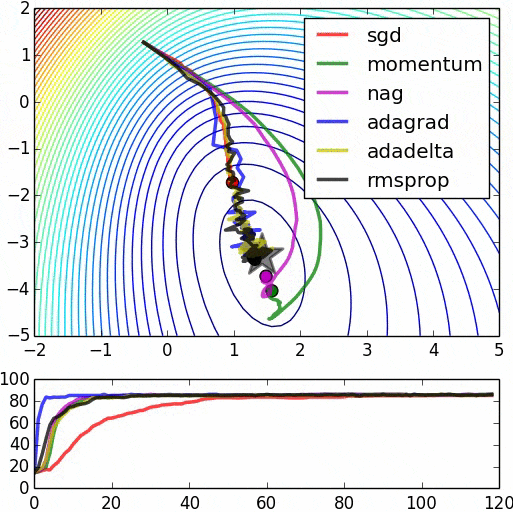
我阅读了许多论文,其中提到“预训练网络可以通过使用RBM或Autoencoders来提高反向传播误差的计算效率”。
1. 如果我理解正确,AutoEncoders 通过学习恒等函数工作,如果隐藏单元少于输入数据的大小,则还会进行压缩。但是,这与如何提高向后传播误差信号的计算效率有什么关系呢?这是因为预先训练的隐藏单元的权重与其初始值相差不大吗?
2. 假设正在阅读此内容的数据科学家已经知道 AutoEncoders 将输入作为目标值,因为它们正在学习恒等函数,这被认为是无监督学习。但是,这种方法是否适用于卷积神经网络,其中第一个隐藏层是特征映射?每个特征映射是通过将学习到的内核与图像中的接受域进行卷积而创建的。这个学习到的内核如何以预训练(无监督方式)获得?
1. 如果我理解正确,AutoEncoders 通过学习恒等函数工作,如果隐藏单元少于输入数据的大小,则还会进行压缩。但是,这与如何提高向后传播误差信号的计算效率有什么关系呢?这是因为预先训练的隐藏单元的权重与其初始值相差不大吗?
2. 假设正在阅读此内容的数据科学家已经知道 AutoEncoders 将输入作为目标值,因为它们正在学习恒等函数,这被认为是无监督学习。但是,这种方法是否适用于卷积神经网络,其中第一个隐藏层是特征映射?每个特征映射是通过将学习到的内核与图像中的接受域进行卷积而创建的。这个学习到的内核如何以预训练(无监督方式)获得?