我有一个得分的相关矩阵,想要在R中使用igraph的Louvain算法进行社区检测。我用
cor2dist将相关矩阵转换为距离矩阵,如下所示:
distancematrix <- cor2dist(correlationmatrix)
这样就得到了一个400 x 400的距离矩阵,距离范围在0到2之间。然后我使用http://kateto.net/networks-r-igraph(3.1节)中的以下方法,制作了边缘列表(距离)和顶点(400个个体)的列表。library(igraph)
test <- as.matrix(distancematrix)
mode(test) <- "numeric"
test2 <- graph.adjacency(test, mode = "undirected", weighted = TRUE, diag = TRUE)
E(test2)$weight
get.edgelist(test2)
接着,我将“起始点”和“终止点”边缘列表及对应的权重写成了csv文件:
edgeweights <-E(test2)$weight
write.csv(edgeweights, file = "edgeweights.csv")
fromtolist <- get.edgelist(test2)
write.csv(fromtolist, file = "fromtolist.csv")
从这两个文件中,我生成了一个名为“nodes.csv”的.csv文件,其中只包含400个个体的所有顶点ID:
id
1
2
3
4
...
400
还有一个名为"edges.csv"的csv文件,它详细描述了每个节点之间的“from”和“to”,并提供了每条边的权重(即距离度量):
from to weight
1 2 0.99
1 3 1.20
1 4 1.48
...
399 400 0.70
我随后尝试使用节点和边列表创建igraph对象,并以以下方式运行louvain聚类:
nodes <- read.csv("nodes.csv", header = TRUE, as.is = TRUE)
edges <- read.csv("edges.csv", header = TRUE, as.is = TRUE)
clustergraph <- graph_from_data_frame(edges, directed = FALSE, vertices = nodes)
clusterlouvain <- cluster_louvain(clustergraph)
不幸的是,这无法正确执行louvain社区检测。我预期这会返回大约2-4个不同的社区,类似于这里可以绘制出来,但是sizes(clusterlouvain)返回:
Community sizes
1
400
这段文字表明所有个体都被归入同一个社区。聚类也立即运行(即几乎没有计算时间),这也让我认为它没有正确工作。
我的问题是:有谁能提供建议,解释为什么cluster_louvain方法没有起作用,只识别出一个社区?我认为可能是我错误地指定了距离矩阵或边/节点,或以其他方式未正确提供正确的输入给cluster_louvain方法。我对R还比较陌生,因此非常感谢任何建议。我已成功地在相同的距离矩阵上使用了其他社区检测方法(即k-means),其识别出2-3个社区,但我想了解这里做错了什么。
我知道有多个关于在R中使用igraph的查询,但我没有找到一个明确指定边和节点格式(从相关性矩阵)的查询,以正确地进行louvain社区检测。
感谢您的任何建议!如果需要,我可以提供更多信息。
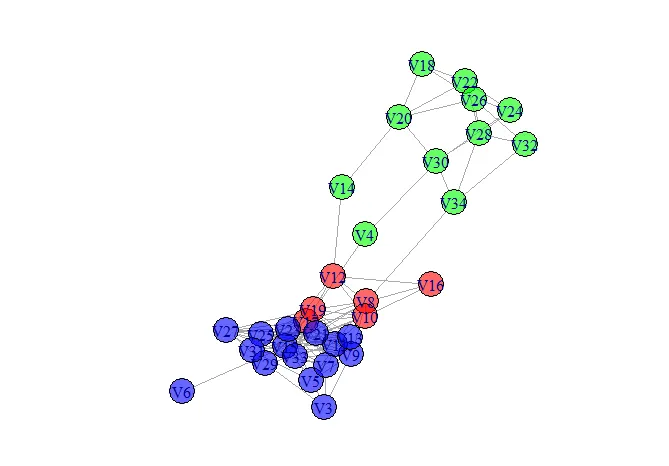
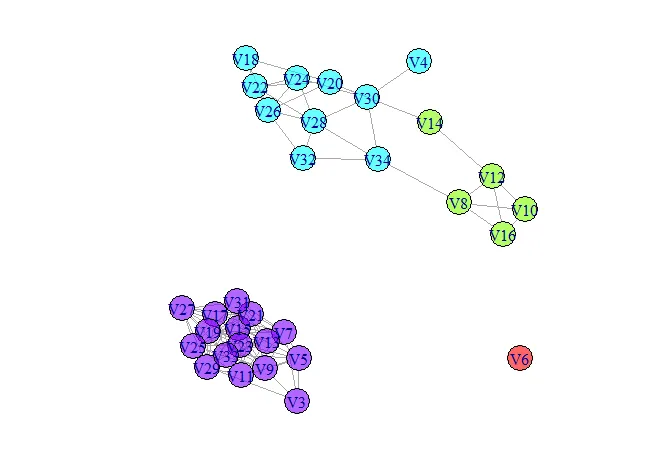
cluster_louvain是否会自动阈值化边缘列表以仅使用更高加权边缘(即更高的相关性)来推导社区。但是在思考后,我意识到cluster_louvain当然会使用所有边缘进行社区检测,因为它不会自动知道边缘表示相关性(或任何其他度量),其中只有更高的值是有意义的;这是我们作为研究人员在相关性/输入矩阵中指定的。再次感谢您有用的解释和解决方案。 - A.Robin