我有一个网络,想使用igraph中的edge_betweenness社区检测算法进行分析。我熟悉NetworkX,但尝试学习igraph,因为它比NetworkX具有更多的社区检测方法。
我的最终目标是运行edge_betweenness社区检测,并找到最优数量的社区,并编写一个CSV文件,其中包含图中每个节点的社区成员资格。
以下是我当前的代码。非常感谢任何能帮助我解决社区成员问题的人。
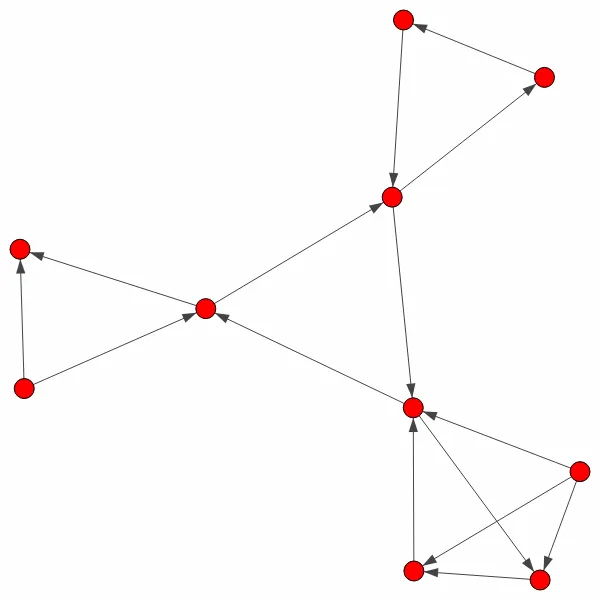
输入数据('network.txt'):
1 2
2 3
2 7
3 1
4 2
4 6
5 4
5 6
7 4
7 8
8 9
9 7
10 7
10 8
10 9
iGraph 代码
import igraph
# load data into a graph
g = igraph.Graph.Read_Ncol('network.txt')
# plot graph
igraph.plot(g)
# identify communities
communities = igraph.community_edge_betweenness()
# not really sure what to do next
num_communities = communities.optimal_count
communities.as_clustering(num_communities)
我应该怎么做才能找到最佳社区数,并将图中每个节点属于的社区写入列表?