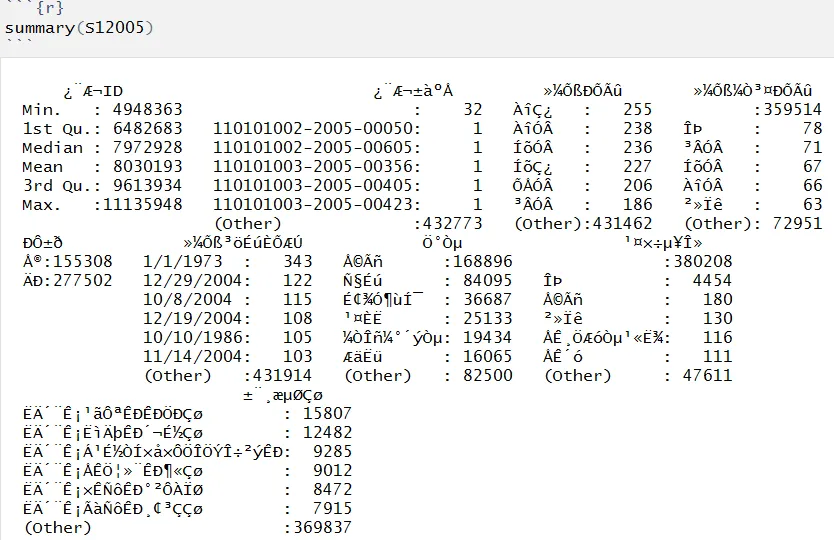
我目前在R Studio中处理大量的中文医疗记录CSV文件,但是遇到了处理汉字字符的问题。特别地,我能够使用R Studio内置的数据查看器以表格形式"查看"(即查看整个数据集),但我无法在R Markdown的代码块输出中渲染它们--即无法“处理”或“交互”它们。
我已经尝试通过
非常感谢您对在R Studio中处理中文字符似乎需要“双重处理”的任何想法!
{kind=link}
{kind=link}
我已经尝试通过
Sys.setlocale(category = "LC_CTYPE", locale = "chs")将系统区域设置为简体中文,通过read.csv('filepath/filename.csv', encoding = "UTF-8", stringsAsFactors = FALSE)使用UTF-8编码读取csv文件,并甚至更改了操作系统语言(Windows 10),但都没有成功。非常感谢您对在R Studio中处理中文字符似乎需要“双重处理”的任何想法!