我正在尝试使用性能分析来查看代码的哪一部分负责最大使用3GB内存(如gc()统计的最大使用内存所报告的,点击此处查看)。我正在这样运行内存分析:
Rprof(line.profiling = TRUE, memory.profiling = TRUE)
graf(...) # ... here I run the profiled code
Rprof(NULL)
summaryRprof(lines = "both", memory = "both")
输出结果如下:
$by.total
total.time total.pct mem.total self.time self.pct
"graf" 299.12 99.69 50814.4 0.02 0.01
#2 299.12 99.69 50814.4 0.00 0.00
"graf.fit.laplace" 299.06 99.67 50787.2 0.00 0.00
"doTryCatch" 103.42 34.47 4339.2 0.00 0.00
"chol" 103.42 34.47 4339.2 0.00 0.00
"tryCatch" 103.42 34.47 4339.2 0.00 0.00
"tryCatchList" 103.42 34.47 4339.2 0.00 0.00
"tryCatchOne" 103.42 34.47 4339.2 0.00 0.00
"chol.default" 101.62 33.87 1087.0 101.62 33.87
graf.fit.laplace.R#46 85.80 28.60 3633.2 0.00 0.00
"backsolve" 78.82 26.27 1635.2 58.40 19.46
我该如何解释`mem.total`?它是什么,单位是什么?我试图查看文档,即`?Rprof`和`?summaryRprof`,但似乎没有很好的说明 :-/ 编辑:这里他们说Rprof "定期探测R的总内存使用情况"。但这不符合50GB,这远远超出了我的内存能力!(现在是8GB物理内存+12 GB页面文件)。
同样,正如R Yoda所指出的那样,`?summaryRprof`表示,使用`memory = "both"`意味着"总内存的变化"。但它到底是什么(是总内存还是总内存的变化),以及它如何与50GB数字相吻合?
编辑:在profvis中进行的同样分析-当我悬停在50812上时,它显示“内存分配(MB)”,并在靠近该垂直线的黑色条上悬停“达到峰值内存分配和释放的百分比”。不确定这是什么意思...这大约是50 GB,这意味着可能是所有分配的总和(??)...绝对不是峰值内存使用:
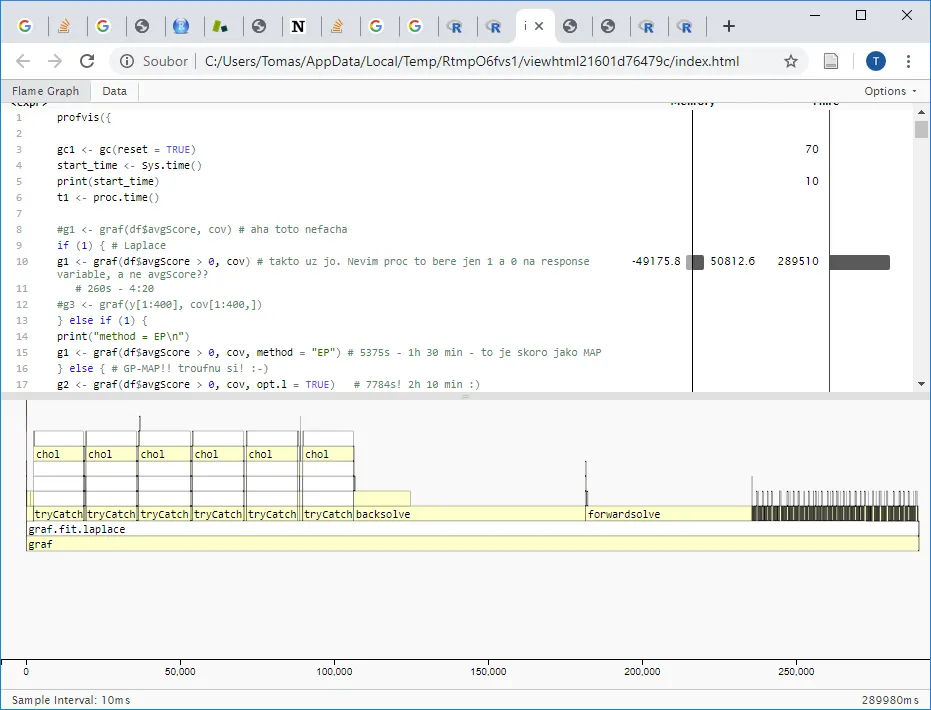
profvis给了我相同的数字,并标记为 MB!这可能意味着该书存在错误!但无论如何,似乎这是所有分配总和,而不是单个时间内使用的内存。请查看我的更新。 - Tomas?summaryRprof提到:“如果 memory = “both”,则是相同的列表,但除了时间之外还会显示内存消耗,以 Mb 为单位。” 所以我认为 MB 是正确的。帮助文档也提到:“如果 memory = “both”,则除了计时数据外还报告总内存的变化(截断为零)”。 - R Yoda