我有一个数据框df,从数据库加载数据。大部分列是JSON字符串,而有些甚至是JSON列表。例如:
id name columnA columnB
1 John {"dist": "600", "time": "0:12.10"} [{"pos": "1st", "value": "500"},{"pos": "2nd", "value": "300"},{"pos": "3rd", "value": "200"}, {"pos": "total", "value": "1000"}]
2 Mike {"dist": "600"} [{"pos": "1st", "value": "500"},{"pos": "2nd", "value": "300"},{"pos": "total", "value": "800"}]
...
正如您所看到的,每个列的json字符串中的元素数量并不相同。
我需要做的是保留普通列(如id和name),并展开json列,如下所示:
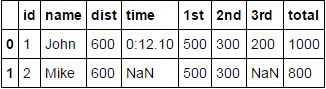
id name columnA.dist columnA.time columnB.pos.1st columnB.pos.2nd columnB.pos.3rd columnB.pos.total
1 John 600 0:12.10 500 300 200 1000
2 Mark 600 NaN 500 300 Nan 800
我已经尝试使用json_normalize如下:
from pandas.io.json import json_normalize
json_normalize(df)
但似乎 keyerror 存在问题。 正确的做法是什么?