我有一个Pandas数据框,其中一列包含JSON数据(JSON结构很简单:只有一级,没有嵌套数据):
ID,Date,attributes
9001,2020-07-01T00:00:06Z,"{"State":"FL","Source":"Android","Request":"0.001"}"
9002,2020-07-01T00:00:33Z,"{"State":"NY","Source":"Android","Request":"0.001"}"
9003,2020-07-01T00:07:19Z,"{"State":"FL","Source":"ios","Request":"0.001"}"
9004,2020-07-01T00:11:30Z,"{"State":"NY","Source":"windows","Request":"0.001"}"
9005,2020-07-01T00:15:23Z,"{"State":"FL","Source":"ios","Request":"0.001"}"
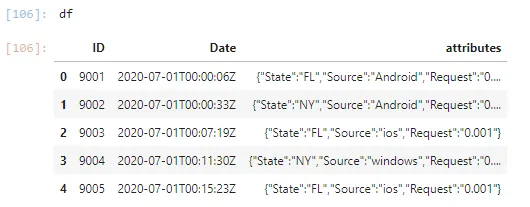
我希望将attributes列中的JSON内容标准化,使JSON属性成为数据框中的每一列。
ID,Date,attributes.State, attributes.Source, attributes.Request
9001,2020-07-01T00:00:06Z,FL,Android,0.001
9002,2020-07-01T00:00:33Z,NY,Android,0.001
9003,2020-07-01T00:07:19Z,FL,ios,0.001
9004,2020-07-01T00:11:30Z,NY,windows,0.001
9005,2020-07-01T00:15:23Z,FL,ios,0.001
我一直在尝试使用Pandas json_normalize,它需要一个字典。所以,我想把attributes列转换成字典,但是并没有像预期的那样工作,因为字典的形式如下:
df.attributes.to_dict()
{0: '{"State":"FL","Source":"Android","Request":"0.001"}',
1: '{"State":"NY","Source":"Android","Request":"0.001"}',
2: '{"State":"FL","Source":"ios","Request":"0.001"}',
3: '{"State":"NY","Source":"windows","Request":"0.001"}',
4: '{"State":"FL","Source":"ios","Request":"0.001"}'}
归一化使用键(0、1、2等)作为列名,而不是JSON键。
我感觉我接近了答案,但还不能完全确定如何准确地执行。欢迎任何想法。
谢谢!