我正在创作一个基于软件的3D渲染器,以便了解概念和数学。这很有趣,我有一个漂亮的立方体在网格上旋转,充当一种地板的角色。网格/地板使用线段进行渲染。我使用简单的观察变换来定位和定向虚拟相机。视平面被任意设置为距离“眼睛”处的距离n,或者在
除了一件事情之外,一切都正常(从对象到世界到相机空间的变换、裁剪、投影、剔除、渲染)。当渲染网格时,线段端点可能跨越虚拟相机的视平面。我想呈现可见部分,所以要对视平面进行裁剪。裁剪后的端点被投影到视平面上。投影公式如下:
z = -n处。除了一件事情之外,一切都正常(从对象到世界到相机空间的变换、裁剪、投影、剔除、渲染)。当渲染网格时,线段端点可能跨越虚拟相机的视平面。我想呈现可见部分,所以要对视平面进行裁剪。裁剪后的端点被投影到视平面上。投影公式如下:
p'(x) = -n * p(x) / p(z)
p'(y) = -n * p(y) / p(z)
所有可能可见的点都会满足 p(z) ≤ -n。被剪裁到视平面上的点满足 p(z) = -n。因此,我实际上有:
p'(x) = p(x)
p'(y) = p(y)
这类点需要进行正投影。
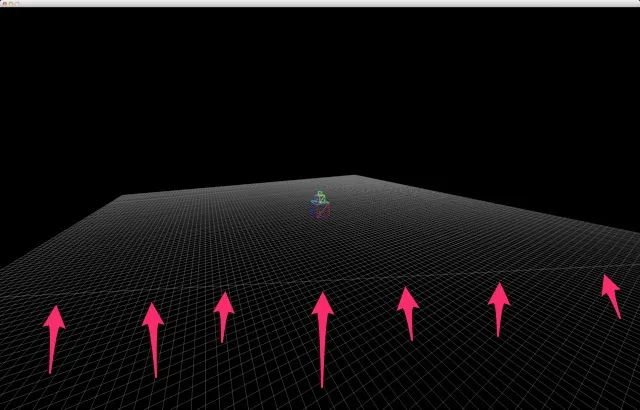
这里的值很容易超出视图平面窗口,导致视口变换将这些点远离操作系统窗口的范围。效果是我看到偶尔会有杂线飞来飞去,非常糟糕。
除了像OpenGL那样做所有事情(我会用OpenGL!),我还漏掉了什么?
感谢您阅读到这里!
这是一个屏幕截图,显示了异常情况。网格的近右侧角刚好不在视野内。向近左侧角的线段在相机后方,因此被剪裁。端点经历了(错误的)正交投影,并最终远离实际位置。
我还没有执行任何视锥体裁剪(但我应该吗?)