背景:
1. 使用Python执行SQL并使用Pandas将输出保存为DataFrame格式。 2. 将输出追加到现有的Excel文件中作为一个新工作表。
以下是我的代码:
1. 使用Python执行SQL并使用Pandas将输出保存为DataFrame格式。 2. 将输出追加到现有的Excel文件中作为一个新工作表。
以下是我的代码:
from pandas import ExcelWriter
sql_20 = ''''''
db = cx_Oracle.connect('*****', '*******', '**********')
conn = db.cursor()
conn.execute(sql_20)
df = pandas.read_sql_query(sql_20,db)
print(df)
with ExcelWriter('GUCS6J-Job Data.xlsx', mode='a') as writer:
df.to_excel(writer, sheet_name=str(20))
writer.save()
数据库: Oracle
A列数据类型: date
从Oracle中的SQL结果:

从Python中的DataFrame打印输出:

到目前为止一切顺利
但是我在Excel工作表中得到的结果是:

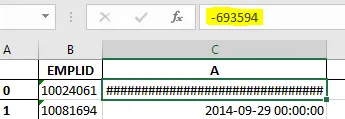
我很好奇为什么会出现'##################',并且这个单元格的值是-693594。
我希望在Excel文件中获得与DataFrame打印输出相同的结果。
df['A']的数据类型是什么? - Umar.Hpd.to_datetime('01-Jan-01')返回2001-01-01,将您的日期转换为有效的 Pandas 日期时间格式df['date'] = pd.to_datetime(df['date'])在我的机器上进行了测试,并且可以在 Excel 中查看。 - Umar.Hdf.to_excel('GUCS6J-Job Data.xlsx', sheet_name=str(20))。 - NotAName