我收集了来自传感器的数据,看起来像:
sec nanosec value
1001 1 0.2
1001 2 0.2
1001 3 0.2
1002 1 0.1
1002 2 0.2
1002 3 0.1
1003 1 0.2
1003 2 0.2
1003 3 0.1
1004 1 0.2
1004 2 0.2
1004 3 0.2
1004 4 0.1
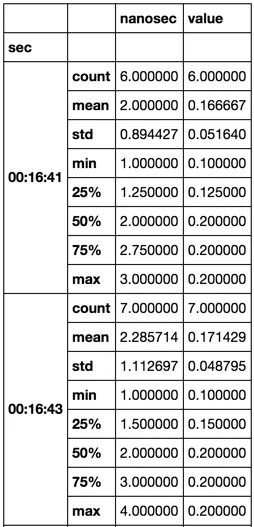
我想每2秒钟计算一次列的 平均数、标准差 以及其他统计数据,如最大值、最小值等。
例如,(1001, 1002) 的平均值=0.167,(1003,1004) 的平均值=0.17。
根据教程http://earthpy.org/pandas-basics.html,我认为我应该将它转换为时间序列,然后使用 pandas 中的 rolling_means 函数进行计算。但由于我不熟悉时间序列数据,所以我不确定这是否是正确的方法。 还有一个问题是,如何指定频率进行转换,因为第一秒钟的观察次数少于实际数据中的100个读数,之后才有100个观察值(从第1002秒开始)。
我也可以简单地对“秒”进行分组,但它会将每秒的读数分组而不是每2秒钟一组,那么如何结合两个连续的分组观察值进行分析呢?
0.18.1,我认为你可以升级pandas。 - jezrael