我想要更改Pandas DataFrame的列标签从
['$a', '$b', '$c', '$d', '$e']
to
['a', 'b', 'c', 'd', 'e']
['$a', '$b', '$c', '$d', '$e']
to
['a', 'b', 'c', 'd', 'e']
除了已提供的解决方案外,在读取文件时,您可以替换所有列。 我们可以使用names和header = 0来完成这项任务。
首先,我们创建一个列名列表,以便作为我们的列名称:
import pandas as pd
ufo_cols = ['city', 'color reported', 'shape reported', 'state', 'time']
ufo.columns = ufo_cols
ufo = pd.read_csv('link to the file you are using', names = ufo_cols, header = 0)
import pandas as pd
import re
srch = re.compile(r"\w+")
data = pd.read_csv("CSV_FILE.csv")
cols = data.columns
new_cols = list(map(lambda v:v.group(), (list(map(srch.search, cols)))))
data.columns = new_cols
下面是一个我喜欢使用的小巧函数,可以减少打字:
def rename(data, oldnames, newname):
if type(oldnames) == str: # Input can be a string or list of strings
oldnames = [oldnames] # When renaming multiple columns
newname = [newname] # Make sure you pass the corresponding list of new names
i = 0
for name in oldnames:
oldvar = [c for c in data.columns if name in c]
if len(oldvar) == 0:
raise ValueError("Sorry, couldn't find that column in the dataset")
if len(oldvar) > 1: # Doesn't have to be an exact match
print("Found multiple columns that matched " + str(name) + ": ")
for c in oldvar:
print(str(oldvar.index(c)) + ": " + str(c))
ind = input('Please enter the index of the column you would like to rename: ')
oldvar = oldvar[int(ind)]
if len(oldvar) == 1:
oldvar = oldvar[0]
data = data.rename(columns = {oldvar : newname[i]})
i += 1
return data
In [2]: df = pd.DataFrame(np.random.randint(0, 10, size=(10, 4)), columns = ['col1', 'col2', 'omg', 'idk'])
# First list = existing variables
# Second list = new names for those variables
In [3]: df = rename(df, ['col', 'omg'],['first', 'ohmy'])
Found multiple columns that matched col:
0: col1
1: col2
Please enter the index of the column you would like to rename: 0
In [4]: df.columns
Out[5]: Index(['first', 'col2', 'ohmy', 'idk'], dtype='object')
我需要为XGBoost重命名特征,但它不喜欢以下任何一个名称:
import re
regex = r"[!\"#$%&'()*+,\-.\/:;<=>?@[\\\]^_`{|}~ ]+"
X_trn.columns = X_trn.columns.str.replace(regex, '_', regex=True)
X_tst.columns = X_tst.columns.str.replace(regex, '_', regex=True)
这个页面上没有提到的一个用例是如何通过索引来重命名列,即在特定位置重命名列名。如果列名是唯一的,那么rename()方法就可以使用。例如,如果我们想要重命名第二列,可以使用以下方法。
df = pd.DataFrame({'$A': [1, 2], '$B': ['a', 'b']})
df.rename(columns={df.columns[1]: 'new'}, inplace=True)
# ^^^^^^^^^^^^^ <--- second column is renamed

pd.DataFrame().columns 是一个不可变的 pandas Index 对象,它是建立在一个(可变的)numpy ndarray 上的,可以使用 .values/.to_numpy() 作为视图进行访问。通过索引修改底层数组即可完成任务。# modify the second column name
df = pd.DataFrame([[1, 'a', 1.2], [2, 'b', 3.4]], columns=['$A', '$B', '$B'])
df.columns[1] = 'new' # <---- TypeError
df.columns.values[1] = 'new' # <---- OK
df.columns.to_numpy()[1] = 'new' # <---- OK
set_axis()进行赋值。# change the second column name
df = df.set_axis([*df.columns[:1], 'new', *df.columns[2:]], axis=1)
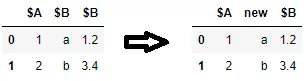
str 方法pd.DataFrame().columns 还定义了一个 .str 访问器,可以调用特定的字符串方法。对于问题中的用例,可以使用 removeprefix() 来删除前导的 '$'。
df = pd.DataFrame({'$A': [1, 2], '$B': ['a', 'b']})
df.columns = df.columns.str.removeprefix('$')
