我想要更改Pandas DataFrame的列标签从
['$a', '$b', '$c', '$d', '$e']
to
['a', 'b', 'c', 'd', 'e']
['$a', '$b', '$c', '$d', '$e']
to
['a', 'b', 'c', 'd', 'e']
我想解释一下幕后发生了什么。
Dataframe是一组Series。
而Series则是一个numpy.array的扩展。
numpy.array具有属性.name。
这就是Series的名称。Pandas很少会使用这个属性,但它仍然存在某些地方,可以用来修改一些Pandas的行为。
这里有很多答案都提到了df.columns属性是一个list,而实际上它是一个Series。这意味着它具有.name属性。
如果您决定填写列Series的名称,会发生以下情况:
df.columns = ['column_one', 'column_two']
df.columns.names = ['name of the list of columns']
df.index.names = ['name of the index']
name of the list of columns column_one column_two
name of the index
0 4 1
1 5 2
2 6 3
请注意,索引的名称始终比其列低一列。
.name 属性有时会残留。如果您设置 df.columns = ['one', 'two'],则 df.one.name 将是 'one'。
如果您设置 df.one.name='three',那么 df.columns 仍将返回 ['one', 'two'],而 df.one.name 将返回 'three'。
pd.DataFrame(df.one) 将返回
three
0 1
1 2
2 3
由于Pandas重复使用已定义的Series的.name,因此会出现这种情况。
Pandas有多种方法可以实现多层次的列名。这并没有太多的魔法,但我也想在我的答案中涵盖这个问题,因为我没有看到任何人在这方面进行讨论。
|one |
|one |two |
0 | 4 | 1 |
1 | 5 | 2 |
2 | 6 | 3 |
可以通过将列设置为列表来轻松实现,像这样:
df.columns = [['one', 'one'], ['one', 'two']]
许多pandas函数都有一个inplace参数。将其设置为True时,转换将直接应用于您调用它的数据框。例如:
df = pd.DataFrame({'$a':[1,2], '$b': [3,4]})
df.rename(columns={'$a': 'a'}, inplace=True)
df.columns
>>> Index(['a', '$b'], dtype='object')
或者,有些情况下您希望保留原始数据框。我经常看到人们陷入这种情况的情况是如果创建数据框是一项昂贵的任务。例如,如果创建数据框需要查询一个雪花数据库。在这种情况下,只需确保 inplace 参数设置为 False。
df = pd.DataFrame({'$a':[1,2], '$b': [3,4]})
df2 = df.rename(columns={'$a': 'a'}, inplace=False)
df.columns
>>> Index(['$a', '$b'], dtype='object')
df2.columns
>>> Index(['a', '$b'], dtype='object')
假设您的数据集名称为df,并且df有。
df = ['$a', '$b', '$c', '$d', '$e']`
所以,要重命名它们,我们只需要这样做。
df.columns = ['a','b','c','d','e']
让我们通过一个小例子来理解重命名...
使用映射重命名列:
df = pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6]}) # Creating a df with column name A and B
df.rename({"A": "new_a", "B": "new_b"}, axis='columns', inplace =True) # Renaming column A with 'new_a' and B with 'new_b'
Output:
new_a new_b
0 1 4
1 2 5
2 3 6
使用映射重命名索引/行名称:
df.rename({0: "x", 1: "y", 2: "z"}, axis='index', inplace =True) # Row name are getting replaced by 'x', 'y', and 'z'.
Output:
new_a new_b
x 1 4
y 2 5
z 3 6
假设这是你的数据框。
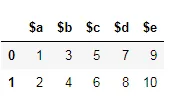
有两种方法可以重命名列。
使用 dataframe.columns=[#list]
df.columns=['a','b','c','d','e']
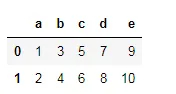
这种方法的局限性在于,如果需要更改一列,就必须传递整个列列表。此外,这种方法不适用于索引标签。 例如,如果您传递了这个:
df.columns = ['a','b','c','d']
这将会抛出一个错误。长度不匹配:期望轴有5个元素,新值只有4个元素。
另一种方法是Pandas的rename()方法,它用于重命名任何索引、列或行。
df = df.rename(columns={'$a':'a'})
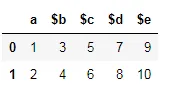
同样地,您可以更改任何行或列。
new_cols = ['a', 'b', 'c', 'd', 'e']
new_names_map = {df.columns[i]:new_cols[i] for i in range(len(new_cols))}
df.rename(new_names_map, axis=1, inplace=True)
columns = df.columns
columns = [row.replace("$", "") for row in columns]
df.rename(columns=dict(zip(columns, things)), inplace=True)
df.head() # To validate the output
最佳方法?我不知道。一种方法 - 是的。
评估所有答案中提出的主要技术的更好方法是使用cProfile来衡量内存和执行时间。 @kadee,@kaitlyn和@eumiro具有最快执行时间的函数 - 尽管这些函数非常快,我们正在比较所有答案的0.000和0.001秒的舍入。 结论:上面的我的答案可能不是“最佳”方法。
import pandas as pd
import cProfile, pstats, re
old_names = ['$a', '$b', '$c', '$d', '$e']
new_names = ['a', 'b', 'c', 'd', 'e']
col_dict = {'$a': 'a', '$b': 'b', '$c': 'c', '$d': 'd', '$e': 'e'}
df = pd.DataFrame({'$a':[1, 2], '$b': [10, 20], '$c': ['bleep', 'blorp'], '$d': [1, 2], '$e': ['texa$', '']})
df.head()
def eumiro(df, nn):
df.columns = nn
# This direct renaming approach is duplicated in methodology in several other answers:
return df
def lexual1(df):
return df.rename(columns=col_dict)
def lexual2(df, col_dict):
return df.rename(columns=col_dict, inplace=True)
def Panda_Master_Hayden(df):
return df.rename(columns=lambda x: x[1:], inplace=True)
def paulo1(df):
return df.rename(columns=lambda x: x.replace('$', ''))
def paulo2(df):
return df.rename(columns=lambda x: x.replace('$', ''), inplace=True)
def migloo(df, on, nn):
return df.rename(columns=dict(zip(on, nn)), inplace=True)
def kadee(df):
return df.columns.str.replace('$', '')
def awo(df):
columns = df.columns
columns = [row.replace("$", "") for row in columns]
return df.rename(columns=dict(zip(columns, '')), inplace=True)
def kaitlyn(df):
df.columns = [col.strip('$') for col in df.columns]
return df
print 'eumiro'
cProfile.run('eumiro(df, new_names)')
print 'lexual1'
cProfile.run('lexual1(df)')
print 'lexual2'
cProfile.run('lexual2(df, col_dict)')
print 'andy hayden'
cProfile.run('Panda_Master_Hayden(df)')
print 'paulo1'
cProfile.run('paulo1(df)')
print 'paulo2'
cProfile.run('paulo2(df)')
print 'migloo'
cProfile.run('migloo(df, old_names, new_names)')
print 'kadee'
cProfile.run('kadee(df)')
print 'awo'
cProfile.run('awo(df)')
print 'kaitlyn'
cProfile.run('kaitlyn(df)')
df = pd.DataFrame({'$a': [1], '$b': [1], '$c': [1], '$d': [1], '$e': [1]})
如果您的新列列表与现有列的顺序相同,则赋值很简单:
new_cols = ['a', 'b', 'c', 'd', 'e']
df.columns = new_cols
>>> df
a b c d e
0 1 1 1 1 1
如果您有一个以旧列名为键的字典,将其映射到新列名,您可以执行以下操作:
d = {'$a': 'a', '$b': 'b', '$c': 'c', '$d': 'd', '$e': 'e'}
df.columns = df.columns.map(lambda col: d[col]) # Or `.map(d.get)` as pointed out by @PiRSquared.
>>> df
a b c d e
0 1 1 1 1 1
如果您没有一个列表或者字典映射,您可以通过列表解析去掉前导的$符号:
如果您没有一个列表或字典的映射,您可以通过列表解析来去除前面的$符号:
df.columns = [col[1:] if col[0] == '$' else col for col in df]
d.get 代替 lambda col: d[col],这样代码就变成了 df.columns.map(d.get)。 - piRSquareddf.rename(index=str, columns={'A':'a', 'B':'b'})
我们可以通过去除原始列标签中不需要的字符(这里是 '$')来替换原始的列标签。
可以通过在df.columns上运行一个for循环并将剥离的列附加到df.columns来完成此操作。
相反,我们可以使用列表推导式在一条语句中整洁地完成此操作,例如以下代码:
df.columns = [col.strip('$') for col in df.columns]
(strip 方法可以用于 Python 中从字符串的开头和结尾删除给定的字符。)