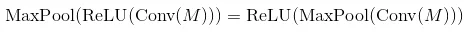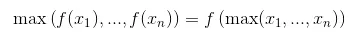这些链接中的理论表明卷积神经网络的顺序为:
卷积层 - 非线性激活函数 - 池化层。
但是,在这些网站的最后一次实现中,它说顺序是:卷积层 - 池化层 - 非线性激活函数
我也尝试了一下探索Conv2D操作的语法,但没有激活函数,只是用翻转的内核进行卷积。有人能帮我解释一下为什么会这样吗?