我正在尝试使用scipy.optimize中的curve_fit将形式为a*x**b+c的幂律拟合到一些数据点上。
以下是MWE:
import numpy as np
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
def func_powerlaw(x, m, c, c0):
return c0 + x**m * c
x = np.array([1.05, 1.0, 0.95, 0.9, 0.85, 0.8, 0.75, 0.7, 0.65, 0.6, 0.55])
y = np.array([1.26, 1.24, 1.2, 1.17, 1.1, 1.01, 0.95, 0.84, 0.75, 0.71, 0.63])
dy = np.array([0.078]*11)
fig, (a1) = plt.subplots(ncols=1,figsize=(10,10))
a1.errorbar(x, y, yerr = dy, ls = '', marker='o')
popt, pcov = curve_fit(func_powerlaw, x, y, sigma = dy, p0 = [0.3, 1, 1], bounds=[(0.1, -2, -2), (0.9, 10, 2)], absolute_sigma=False, maxfev=10000, method = 'trf')
perr=np.sqrt(np.diag(pcov))
xp = np.linspace(x[0],x[-1], 100)
a1.plot(xp, func_powerlaw(xp, *popt), lw=3, zorder = 1, c = 'b')
print(popt, perr)
输出: [0.35609897 3.24929422 -2.] [0.47034928 3.9030258 3.90965249]
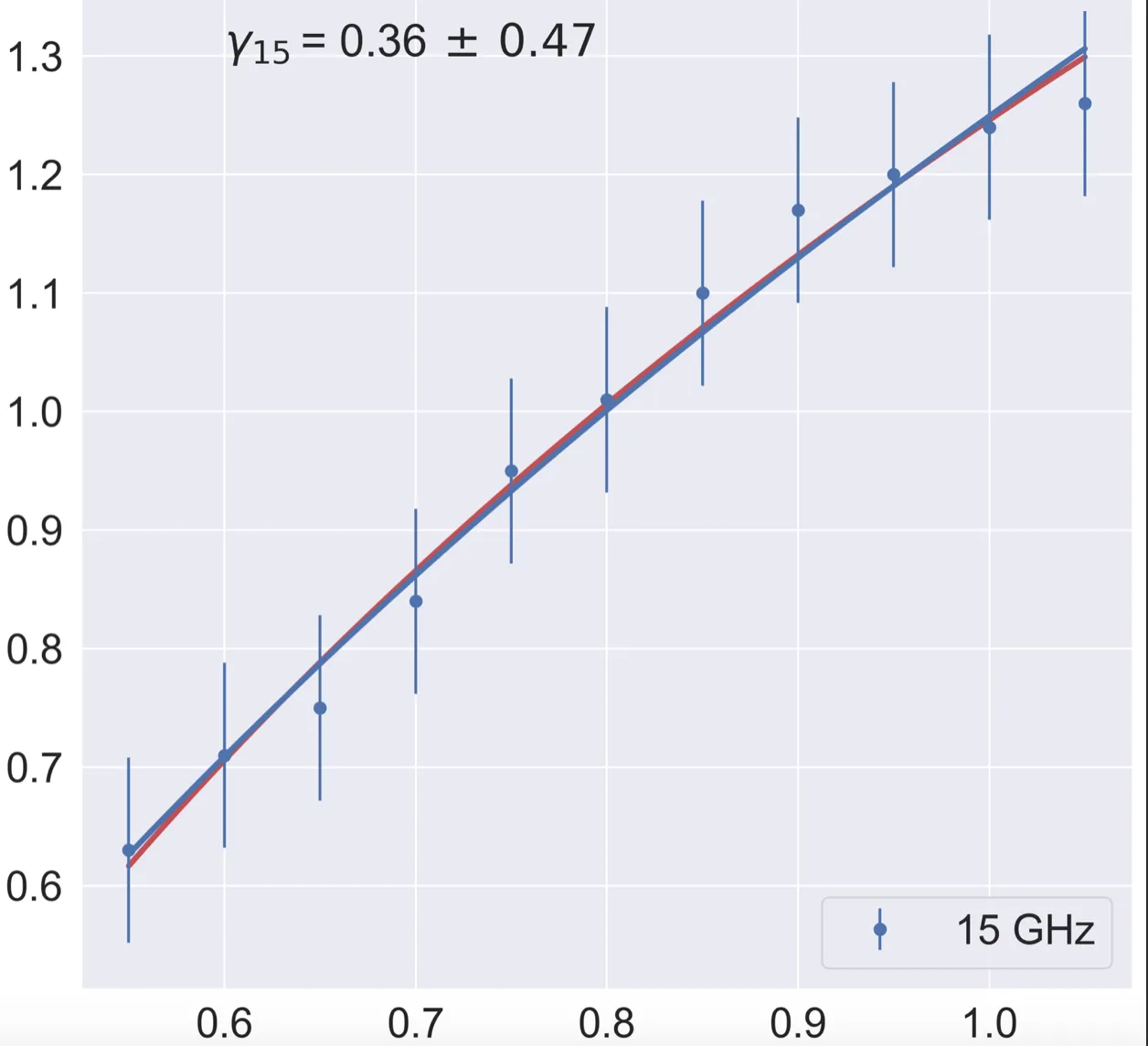
对于所有三个参数,误差都比估计值本身要大。从经验上判断,这不可能是正确的,因为直线非常好地拟合了数据点。
即使我没有设置任何界限和/或初始猜测,数值会改变,但误差仍然太高。
唯一需要的边界是 0.1 <= m <= 0.9。
我做错了什么?
非常感谢您提供的任何帮助!
dy意味着任何值y_i +/- dy都与观测数据y兼容。观测数据的大误差可能导致拟合参数的大误差。尝试以下操作:for y in np.random.uniform(y - dy, y + dy, size=(25, len(y))): ...,然后对每个随机抽样的y(在其不确定性边界内抽样)执行拟合,但不要向拟合过程指示误差(sigma)。然后记录结果参数估计值(popt)并查看np.mean(popts), np.std(popts)。第二个值应该与您的拟合匹配。 - a_guestlmfit,据我所知它是curve_fit的一个包装器,并打印出 χ^2 值。它们很糟糕,甚至不接近1。因此,我认为这不是由于过度拟合引起的。 - Georgesigma和absolute_sigma=False,则没有任何效果,因为如文档中所述,“如果为False(默认),则仅相对大小的sigma值才有意义”。然而,似乎这与你手头的问题无关,因为当你完全删除sigma时,仍会导致较大的perr。如果我理解正确,这是你实际上的问题:生成的曲线很好地拟合了数据点(例如从图形或R2分数判断),但报告的perr非常大。 - a_guest