假设我有一个
numpy 数组的例子:import numpy as np
X = np.array([2,5,0,4,3,1])
我还有一个数组列表,例如:
A = [np.array([-2,0,2]), np.array([0,1,2,3,4,5]), np.array([2,5,4,6])]
我希望只保留每个列表中也在X中的项目,我希望以最有效/常见的方式实现。
到目前为止我尝试的解决方案:
- Sort
XusingX.sort(). Find locations of items of each array in
Xusing:locations = [np.searchsorted(X, n) for n in A]Leave only proper ones:
masks = [X[locations[i]] == A[i] for i in range(len(A))] result = [A[i][masks[i]] for i in range(len(A))]
但它不工作,因为第三个数组的位置超出了边界:
locations = [array([0, 0, 2], dtype=int64), array([0, 1, 2, 3, 4, 5], dtype=int64), array([2, 5, 4, 6], dtype=int64)]
如何解决这个问题?
更新
我最终采用了idx[idx==len(Xs)] = 0的解决方案。 我也注意到了回答之间发布的两种不同的方法:将X转换为set vs np.sort。 它们都有优缺点:set操作使用迭代,与numpy方法相比非常慢; 但是np.searchsorted的速度呈对数增长,不像访问set项一样快速。 这就是为什么我决定使用具有巨大大小的数据进行性能比较,特别是对于X,A[0],A[1],A[2]拥有100万个项目的数据。
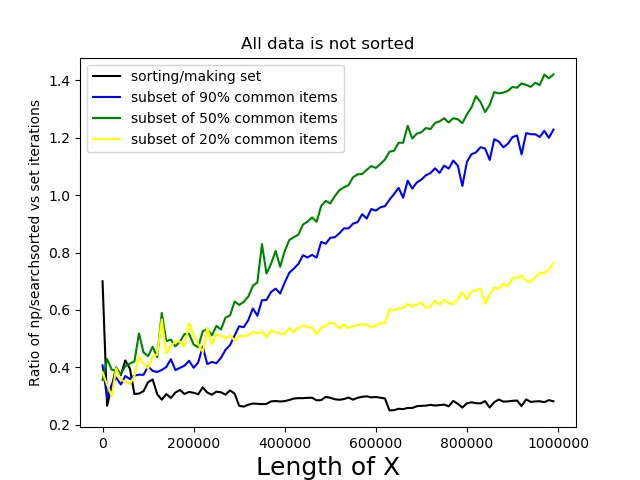
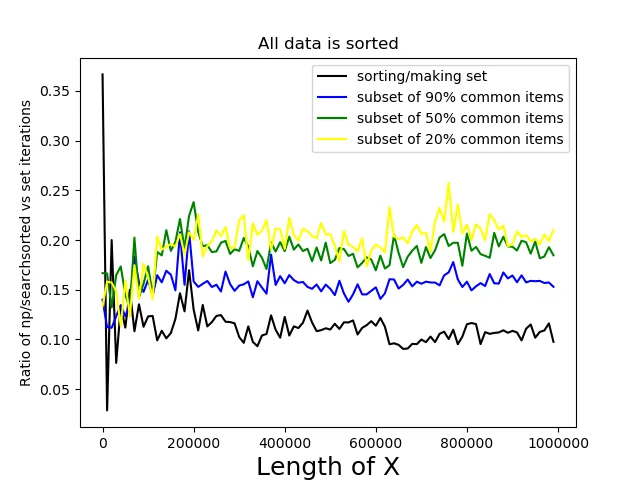
intersect1d是我的想法的一个很好的表达,但我处理的X和A非常巨大,所以我决定先对X进行排序。 - mathfuxset函数要慢得多。 - Daniel F