在跟随 Datashader 示例 展示线条的笔记本电脑 时,输入是一个 Pandas DataFrame(尽管 Dask DataFrame 似乎也可以)。我的数据在一个 NumPy 数组中。我能否使用 Datashader 绘制来自 NumPy 数组的线条,而无需先将它们放入 DataFrame 中?
线条符号 的文档似乎表明这是可能的,但我没有找到示例。我链接的示例笔记本使用
Canvas.line,但我在文档中没有找到它。Canvas.line,但我在文档中没有找到它。df.col_label语法调用它们(而不是df[col_label]语法,也许有一个很好的理由)。根据当前系统,我必须执行以下操作才能将NumPy数组转换为具有Datashader可接受列标签的DataFrame。df = pd.DataFrame(data=data.T)
data_cols = ['c{}'.format(c) for c in df.columns]
df.columns = data_cols
df['x'] = x_values
y_range = data.min(), data.max()
x_range = x_values[0], x_values[-1]
canvas = datashader.Canvas(x_range=x_range, y_range=y_range,
plot_height=300, plot_width=900)
aggs = collections.OrderedDict((c, canvas.line(df, 'q', c)) for c in data_cols)
merged = xarray.concat(saxs_aggs.values(), dim=pd.Index(cols, name='cols'))
saxs_img = datashader.transfer_functions.shade(merged.sum(dim='cols'),
how='eq_hist')
data_cols变量是非常重要的,而不仅仅是使用df.columns,因为它必须排除x列(这一点最初并不直观)。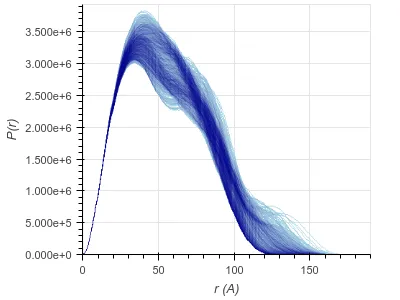
OrderedDict和xarray.concat方法在应用于多个数据曲线时非常缓慢。以下示例演示了一种更快的方法。有关计时和进一步讨论,请参见此 GitHub 问题。
import pandas as pd
import numpy as np
import datashader
import bokeh.plotting
import collections
import xarray
import time
from bokeh.palettes import Colorblind7 as palette
bokeh.plotting.output_notebook()
# create some data worth plotting
nx = 50
x = np.linspace(0, np.pi * 2, nx)
y = np.sin(x)
n = 10000
data = np.empty([n+1, len(y)])
data[0] = x
prng = np.random.RandomState(123)
# scale the data using a random normal distribution
offset = prng.normal(0, 0.1, n).reshape(n, -1)
data[1:] = y
data[1:] += offset
# make some data noisy
n_noisy = prng.randint(0, n,5)
for i in n_noisy:
data[i+1] += prng.normal(0, 0.5, nx)
dfs = []
split = pd.DataFrame({'x': [np.nan]})
for i in range(len(data)-1):
x = data[0]
y = data[i+1]
df = pd.DataFrame({'x': x, 'y': y})
dfs.append(df)
dfs.append(split)
df = pd.concat(dfs, ignore_index=True)
canvas = datashader.Canvas(x_range=x_range, y_range=y_range,
plot_height=300, plot_width=300)
agg = canvas.line(df, 'x', 'y', datashader.count())
img = datashader.transfer_functions.shade(agg, how='eq_hist')
img
