我正在尝试使用OpenCV来估计相机之间的一个姿态,利用SIFT特征跟踪、FLANN匹配和基础矩阵及本质矩阵的后续计算。在分解本质矩阵后,我检查了退化构型并获得了“正确”的R和t。
问题是它们似乎从未正确过。我包含了一些图像对:
- 图像2沿着Y轴旋转45度并与图像1保持相同位置。
图像对
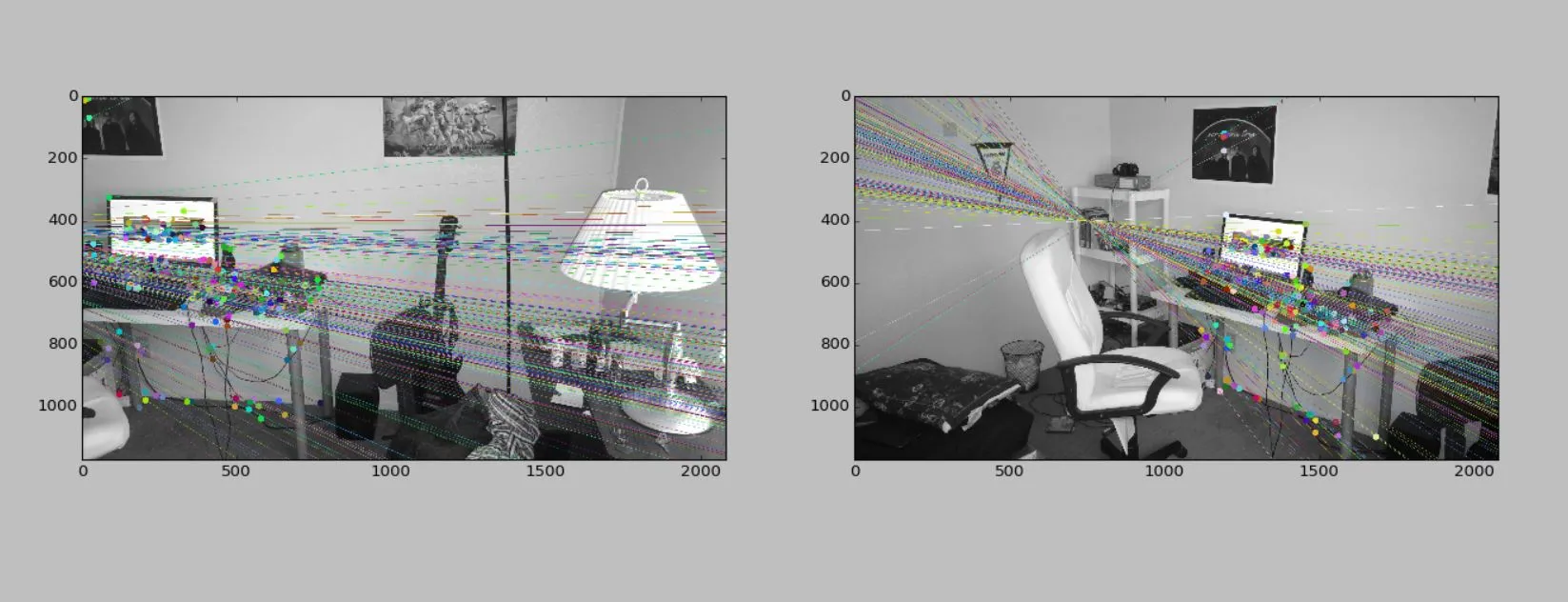
结果
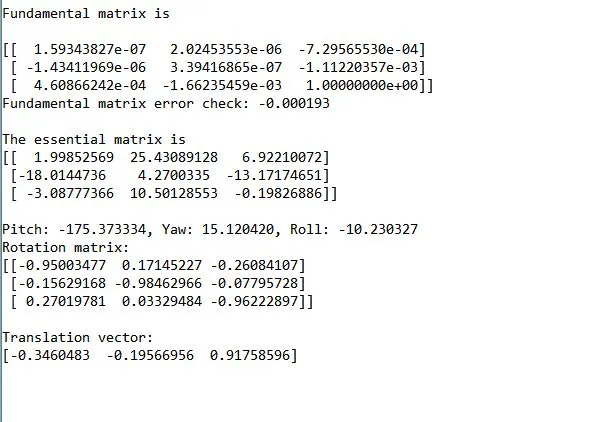
- 图像2是从负X方向大约几米处拍摄的,稍微向负Y方向移动了一点。相机姿态沿Y轴旋转了大约45-60度。
图像对
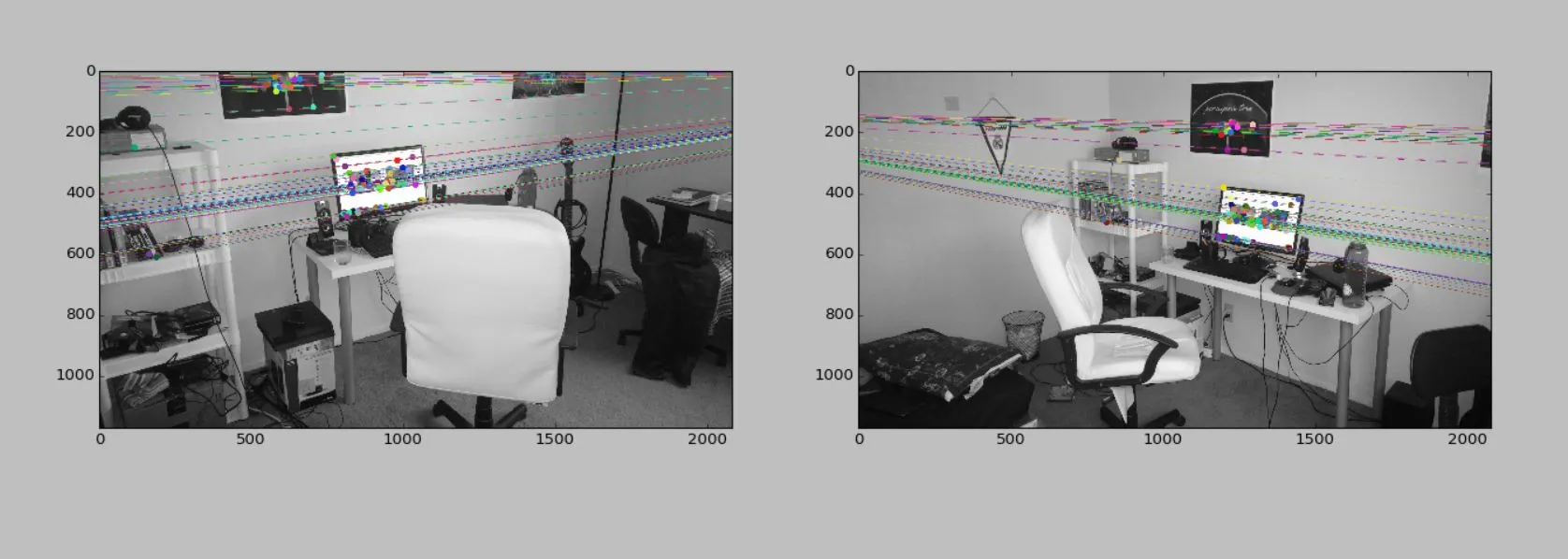
结果
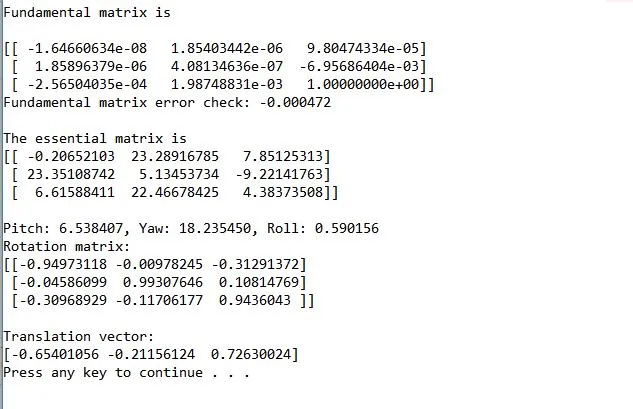
我是否在根本上错过了什么?假设程序正确理解了对极几何,可能会发生什么导致完全错误的姿态?我正在检查以确保点位于两个相机的前面。任何想法/建议都将非常有帮助。谢谢!
编辑:尝试使用间隔的两个不同校准的相机进行相同的技术,并计算本质矩阵为K2'.F.K1,但是仍然偏离了很远的平移和旋转。
参考代码链接:Code
import cv2
import numpy as np
from matplotlib import pyplot as plt
# K2 = np.float32([[1357.3, 0, 441.413], [0, 1355.9, 259.393], [0, 0, 1]]).reshape(3,3)
# K1 = np.float32([[1345.8, 0, 394.9141], [0, 1342.9, 291.6181], [0, 0, 1]]).reshape(3,3)
# K1_inv = np.linalg.inv(K1)
# K2_inv = np.linalg.inv(K2)
K = np.float32([3541.5, 0, 2088.8, 0, 3546.9, 1161.4, 0, 0, 1]).reshape(3,3)
K_inv = np.linalg.inv(K)
def in_front_of_both_cameras(first_points, second_points, rot, trans):
# check if the point correspondences are in front of both images
rot_inv = rot
for first, second in zip(first_points, second_points):
first_z = np.dot(rot[0, :] - second[0]*rot[2, :], trans) / np.dot(rot[0, :] - second[0]*rot[2, :], second)
first_3d_point = np.array([first[0] * first_z, second[0] * first_z, first_z])
second_3d_point = np.dot(rot.T, first_3d_point) - np.dot(rot.T, trans)
if first_3d_point[2] < 0 or second_3d_point[2] < 0:
return False
return True
def drawlines(img1,img2,lines,pts1,pts2):
''' img1 - image on which we draw the epilines for the points in img1
lines - corresponding epilines '''
pts1 = np.int32(pts1)
pts2 = np.int32(pts2)
r,c = img1.shape
img1 = cv2.cvtColor(img1,cv2.COLOR_GRAY2BGR)
img2 = cv2.cvtColor(img2,cv2.COLOR_GRAY2BGR)
for r,pt1,pt2 in zip(lines,pts1,pts2):
color = tuple(np.random.randint(0,255,3).tolist())
x0,y0 = map(int, [0, -r[2]/r[1] ])
x1,y1 = map(int, [c, -(r[2]+r[0]*c)/r[1] ])
cv2.line(img1, (x0,y0), (x1,y1), color,1)
cv2.circle(img1,tuple(pt1), 10, color, -1)
cv2.circle(img2,tuple(pt2), 10,color,-1)
return img1,img2
img1 = cv2.imread('C:\\Users\\Sai\\Desktop\\room1.jpg', 0)
img2 = cv2.imread('C:\\Users\\Sai\\Desktop\\room0.jpg', 0)
img1 = cv2.resize(img1, (0,0), fx=0.5, fy=0.5)
img2 = cv2.resize(img2, (0,0), fx=0.5, fy=0.5)
sift = cv2.SIFT()
# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# FLANN parameters
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50) # or pass empty dictionary
flann = cv2.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
good = []
pts1 = []
pts2 = []
# ratio test as per Lowe's paper
for i,(m,n) in enumerate(matches):
if m.distance < 0.7*n.distance:
good.append(m)
pts2.append(kp2[m.trainIdx].pt)
pts1.append(kp1[m.queryIdx].pt)
pts2 = np.float32(pts2)
pts1 = np.float32(pts1)
F, mask = cv2.findFundamentalMat(pts1,pts2,cv2.FM_RANSAC)
# Selecting only the inliers
pts1 = pts1[mask.ravel()==1]
pts2 = pts2[mask.ravel()==1]
F, mask = cv2.findFundamentalMat(pts1,pts2,cv2.FM_8POINT)
print "Fundamental matrix is"
print
print F
pt1 = np.array([[pts1[0][0]], [pts1[0][1]], [1]])
pt2 = np.array([[pts2[0][0], pts2[0][1], 1]])
print "Fundamental matrix error check: %f"%np.dot(np.dot(pt2,F),pt1)
print " "
# drawing lines on left image
lines1 = cv2.computeCorrespondEpilines(pts2.reshape(-1,1,2), 2,F)
lines1 = lines1.reshape(-1,3)
img5,img6 = drawlines(img1,img2,lines1,pts1,pts2)
# drawing lines on right image
lines2 = cv2.computeCorrespondEpilines(pts1.reshape(-1,1,2), 1,F)
lines2 = lines2.reshape(-1,3)
img3,img4 = drawlines(img2,img1,lines2,pts2,pts1)
E = K.T.dot(F).dot(K)
print "The essential matrix is"
print E
print
U, S, Vt = np.linalg.svd(E)
W = np.array([0.0, -1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0]).reshape(3, 3)
first_inliers = []
second_inliers = []
for i in range(len(pts1)):
# normalize and homogenize the image coordinates
first_inliers.append(K_inv.dot([pts1[i][0], pts1[i][1], 1.0]))
second_inliers.append(K_inv.dot([pts2[i][0], pts2[i][1], 1.0]))
# Determine the correct choice of second camera matrix
# only in one of the four configurations will all the points be in front of both cameras
# First choice: R = U * Wt * Vt, T = +u_3 (See Hartley Zisserman 9.19)
R = U.dot(W).dot(Vt)
T = U[:, 2]
if not in_front_of_both_cameras(first_inliers, second_inliers, R, T):
# Second choice: R = U * W * Vt, T = -u_3
T = - U[:, 2]
if not in_front_of_both_cameras(first_inliers, second_inliers, R, T):
# Third choice: R = U * Wt * Vt, T = u_3
R = U.dot(W.T).dot(Vt)
T = U[:, 2]
if not in_front_of_both_cameras(first_inliers, second_inliers, R, T):
# Fourth choice: R = U * Wt * Vt, T = -u_3
T = - U[:, 2]
# Computing Euler angles
thetaX = np.arctan2(R[1][2], R[2][2])
c2 = np.sqrt((R[0][0]*R[0][0] + R[0][1]*R[0][1]))
thetaY = np.arctan2(-R[0][2], c2)
s1 = np.sin(thetaX)
c1 = np.cos(thetaX)
thetaZ = np.arctan2((s1*R[2][0] - c1*R[1][0]), (c1*R[1][1] - s1*R[2][1]))
print "Pitch: %f, Yaw: %f, Roll: %f"%(thetaX*180/3.1415, thetaY*180/3.1415, thetaZ*180/3.1415)
print "Rotation matrix:"
print R
print
print "Translation vector:"
print T
plt.subplot(121),plt.imshow(img5)
plt.subplot(122),plt.imshow(img3)
plt.show()