在stl开始时,我们找到
x <- na.action(as.ts(x))
不久之后
period <- frequency(x)
if (period < 2 || n <= 2 * period)
stop("series is not periodic or has less than two periods")
也就是说,在na.action(as.ts(x))之后,stl期望x是ts对象(否则period == 1)。首先我们来看一下na.omit和na.exclude。
很明显,在getAnywhere("na.omit.ts")的结尾处,我们找到:
if (any(is.na(object)))
stop("time series contains internal NAs")
这很简单,不能进行任何操作(na.omit 不会从 ts 对象中排除 NAs)。现在,getAnywhere("na.exclude.default") 会排除 NA 观测值,但会返回一个类为 exclude 的对象:
attr(omit, "class") <- "exclude"
这是一种不同的情况。如上所述,stl期望na.action(as.ts(x))为ts,但na.exclude(as.ts(x))的类别为exclude。
因此,如果对于NAs的排除满意,例如:
nottem[3] <- NA
frequency(nottem)
na.new <- function(x) ts(na.exclude(x), frequency = 12)
stl(nottem, na.action = na.new, s.window = "per")
工作。通常情况下,stl 无法处理NA值(即使用 na.action = na.pass时),它会在Fortran深处崩溃(请参见完整的源代码此处):
z <- .Fortran(C_stl, ...
与na.new的替代方法并不令人愉悦:
na.contiguous - 查找时间序列对象中最长连续的非缺失值。na.approx,na.locf来自zoo或其他插值函数。- 关于这个我不太确定,但在Python中可以找到另一个Fortran实现这里。如果该模块确实允许缺失值,可以使用Python或可能安装源代码修改后的R。
正如我们可以在论文中看到的那样,在调用stl之前,没有一些简单的处理缺失值的过程(例如在一开始近似它们),可以应用于时间序列。鉴于原始实现相当冗长,我会考虑一些其他替代方法而不是全新的实现。
更新:当存在NAs时,一个在许多方面都相当优化的选择可能是zoo中的na.approx,因此让我们检查其性能,即使用na.approx比较具有完整数据集和具有一些NAs的结果的stl。我使用MAPE作为准确度的度量标准,但仅适用于趋势,因为季节分量和余数穿越零点并会扭曲结果。NAs的位置是随机选择的。
library(zoo)
library(plyr)
library(reshape)
library(ggplot2)
mape <- function(f, x) colMeans(abs(1 - f / x) * 100)
stlCheck <- function(data, p = 3, ...){
set.seed(20130201)
pos <- lapply(3^(0:p), function(x) sample(1:length(data), x))
datasetsNA <- lapply(pos, function(x) {data[x] <- NA; data})
original <- data.frame(stl(data, ...)$time.series, stringsAsFactors = FALSE)
original$id <- "Original"
datasetsNA <- lapply(datasetsNA, function(x)
data.frame(stl(x, na.action = na.approx, ...)$time.series,
id = paste(sum(is.na(x)), "NAs"),
stringsAsFactors = FALSE))
stlAll <- rbind.fill(c(list(original), datasetsNA))
stlAll$Date <- time(data)
stlAll <- melt(stlAll, id.var = c("id", "Date"))
results <- data.frame(trend = sapply(lapply(datasetsNA, '[', i = "trend"), mape, original[, "trend"]))
results$id <- paste(3^(0:p), "NAs")
results <- melt(results, id.var = "id")
results$x <- min(stlAll$Date) + diff(range(stlAll$Date)) / 4
results$y <- min(original[, "trend"]) + diff(range(original[, "trend"])) / (4 * p) * (0:p)
results$value <- round(results$value, 2)
ggplot(stlAll, aes(x = Date, y = value, colour = id, group = id)) + geom_line() +
facet_wrap(~ variable, scales = "free_y") + theme_bw() +
theme(legend.title = element_blank(), strip.background = element_rect(fill = "white")) +
labs(x = NULL, y = NULL) + scale_colour_brewer(palette = "Set1") +
lapply(unique(results$id), function(z)
geom_text(data = results, colour = "black", size = 3,
aes(x = x, y = y, label = paste0("MAPE (", id, "): ", value, "%"))))
}
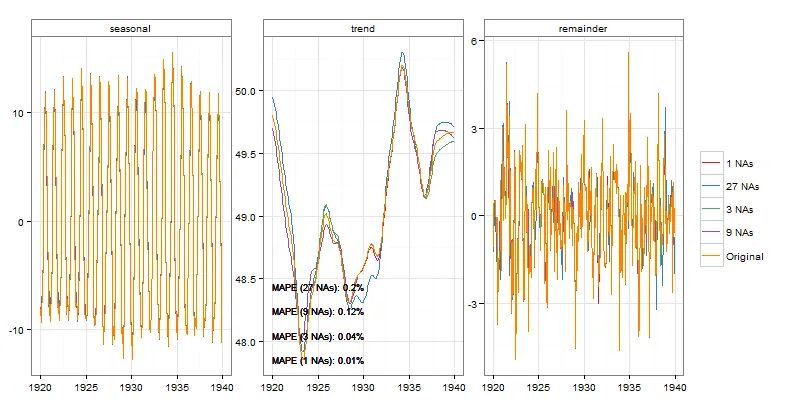
nottem, 240个观测值
stlCheck(nottem, s.window = 4, t.window = 50, t.jump = 1)
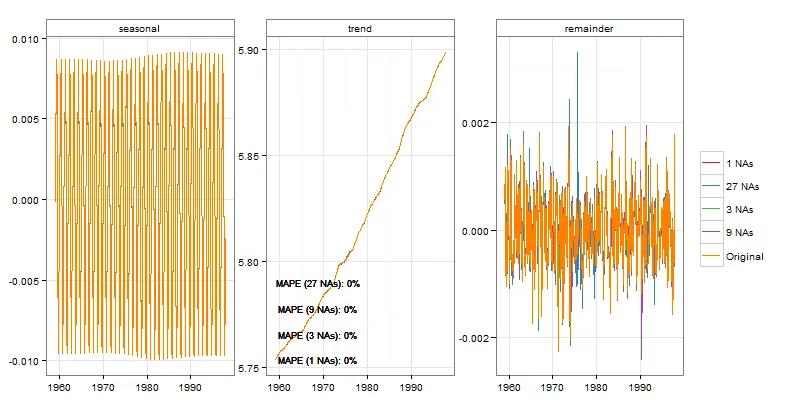
co2,共468个观测值
stlCheck(log(co2), s.window = 21)
mdeaths,72个观测值
stlCheck(mdeaths, s.window = "per")
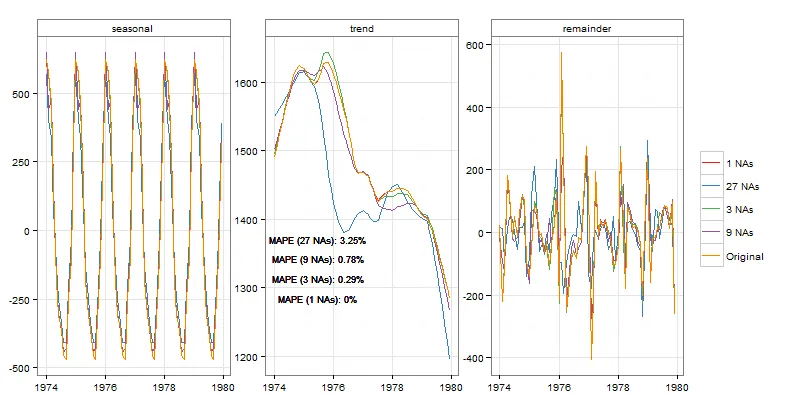
从视觉上,我们确实可以看到案例1和3之间趋势上的一些差异。但在案例1中这些差异相当小,在考虑样本量(72)的情况下,在案例3中也是可以接受的。
zoo包中的na.approx函数来插值你的缺失数据。 - Fernandostlplus包可以处理时间序列分解中的缺失值。Rbeast可能是另一个选择;它是一种贝叶斯算法,不同于只能分解时间序列的stl,Rbeast可以同时进行时间序列分解和变点检测,并允许存在缺失值。这里有一个例子:library(Rbeast);co2[ sample(1:length(co2), 200) ]=NA;plot(beast(co2))。 - zhaokg