我训练了一个二元分类模型,测试准确率达到了98%,训练准确率达到了99%。
今天我想要计算混淆矩阵,并使用以下代码进行计算。
model = load_model("model.h5")
testGenerator = ImageDataGenerator(rotation_range=5,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=False,
fill_mode='nearest'
)
testData = testGenerator.flow_from_directory(
'Location',
target_size=(74,448),
batch_size=15,
class_mode='binary',
shuffle=False
)
proba = model.predict_generator(testData,steps=3000//15)
y_true = np.array([0] * 1482 + [1] * 1482 )
y_pred = proba > 0.5
print(confusion_matrix(y_true, y_pred))
我收到了这个混淆矩阵:
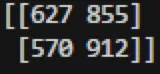
如sklearn所说:
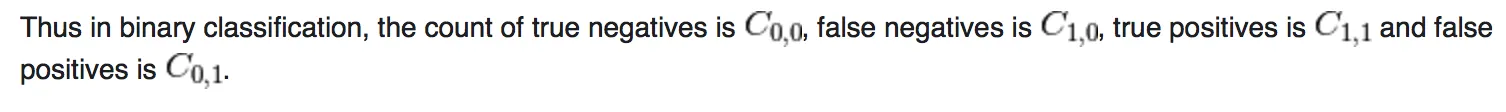
它表明假阴性和假阳性都很高。因为我的测试准确率达到了98%,这怎么可能呢?我已经多次使用该模型生成预测(使用model.predict()函数)并手动检查过,每次都给出了正确的分类。
有什么办法可以获得准确的结果吗?
shuffle=false来实现这个功能。 - Samitha Nanayakkara