我不确定如何在使用dropna()后重置索引。我有
df_all = df_all.dropna()
df_all.reset_index(drop=True)
但是在运行我的代码后,行索引会跳过一些步骤。例如,它会变成0、1、2、4等等。
您发布的代码已经实现了您想要的功能,但并没有在原地进行操作。尝试在reset_index()中添加inplace=True或将结果重新赋值给df_all. 请注意,您也可以在dropna()中使用inplace=True,因此:
df_all.dropna(inplace=True)
df_all.reset_index(drop=True, inplace=True)
一切都在原地完成。或者,
df_all = df_all.dropna()
df_all = df_all.reset_index(drop=True)
重新分配 df_all。
dropna 现在支持 ignore_index=Truepandas >= 2.0
df
A B C
0 1.0 5.0 9
1 2.0 NaN 10
2 NaN 7.0 11
3 4.0 8.0 12
df.dropna() # by default, dropna does not reset the index
A B C
0 1.0 5.0 9
3 4.0 8.0 12
df.dropna(ignore_index=True) # now resets the index
A B C
0 1.0 5.0 9
1 4.0 8.0 12
这样可以跳过后续的reset_index调用。
在GH31725中实现。
对于旧版的pandas(< 2.0)
df.dropna().reset_index(drop=True)
A B C
0 1.0 5.0 9
1 4.0 8.0 12
你可以链式调用方法,将其写成一行代码:
df = df.dropna().reset_index(drop=True)
您也可以使用set_axis()将索引重置为默认值。
df.dropna(inplace=True)
df.set_axis(range(len(df)), inplace=True)
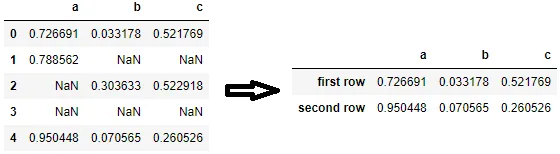
set_axis()非常有用,如果您想将索引重置为默认值以外的任何内容,因为只要长度匹配,就可以使用它将索引更改为任何内容。例如,您可以将其更改为第一行、第二行等等。
df = df.dropna()
df = df.set_axis(['first row', 'second row'])
dropna现在支持ignore_index=True来自动重置索引,因此您可以避免后续的reset_index调用。 - cs95