你可以使用卷积。卷积操作会做类似于这样的事情(更多信息
在这里):
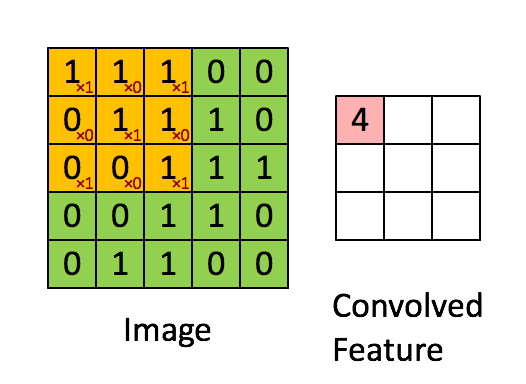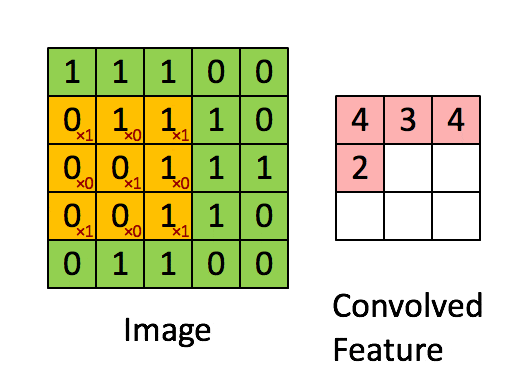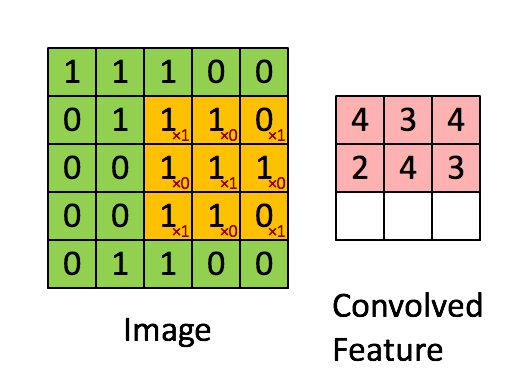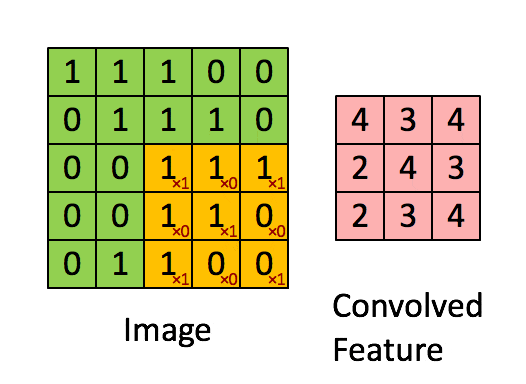
它将通过矩阵乘以您的过滤器或填充矩阵的元素,然后在这种情况下将它们相加。
对于这个问题,让我们首先向数据框添加一个新元素f,以便至少有一行具有多个元素。
>> positions
pos mcap
a 1 1
b 2 4
c 3 3
d 4 2
e 5 5
f 3 2
这些位置也可以被视为:
df = pd.crosstab(positions['pos'], positions['mcap'],
values=positions.index, aggfunc=sum)
df
mcap 1 2 3 4 5
pos
1 a NaN NaN NaN NaN
2 NaN NaN NaN b NaN
3 NaN f c NaN NaN
4 NaN d NaN NaN NaN
5 NaN NaN NaN NaN e
df_ones = df.notnull() * 1
mcap 1 2 3 4 5
pos
1 1 0 0 0 0
2 0 0 0 1 0
3 0 1 1 0 0
4 0 1 0 0 0
5 0 0 0 0 1
我们可以创建一个窗口,通过
df_ones滑动并计算落在窗口内的元素数量之和。这被称为“卷积”(或相关性)。
现在让我们创建一个避开左上角元素的窗口(因此不计入统计),并将其与我们的
df_ones进行卷积以获得结果:
pad = np.ones_like(df.values)
pad[0, 0] = 0
pad
array([[0, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]], dtype=object)
counts = ((signal.correlate(df_ones.values, pad,
mode='full')[-df.shape[0]:,
-df.shape[1]:]) * \
df_ones).unstack().replace(0, np.nan).dropna(
).reset_index().rename(columns={0: 'count'})
mcap pos count
0 1 1 5.0
1 2 3 3.0
2 2 4 1.0
3 3 3 1.0
4 4 2 1.0
positions.reset_index().merge(counts,
how='left').fillna(0
).sort_values('pos').set_index('index')
pos mcap count
index
a 1 1 5.0
b 2 4 1.0
c 3 3 1.0
f 3 2 3.0
d 4 2 1.0
e 5 5 0.0
全部放在一个函数中:
def count_upper(df):
df = pd.crosstab(positions['pos'], positions['mcap'],
values=positions.index, aggfunc=sum)
df_ones = df.notnull() * 1
pad = np.ones_like(df.values)
pad[0, 0] = 0
counts = ((signal.correlate(df_ones.values, pad,
mode='full')[-df.shape[0]:,
-df.shape[1]:]) * df_ones)
counts = counts.unstack().replace(0, np.nan).dropna(
).reset_index().rename(columns={0: 'count'})
result = positions.reset_index().merge(counts,
how='left')
result = result.fillna(0).sort_values('pos').set_index('index')
return result
对于您的示例,结果将与您期望的结果匹配:
positions = pd.DataFrame({"pos" : [1, 2, 3, 4, 5],
"mcap" : [1, 4, 3, 2, 5]},
index = ["a", "b", "c", "d", "e"])
>> count_upper(positions)
pos mcap count
index
a 1 1 4.0
b 2 4 1.0
c 3 3 1.0
d 4 2 1.0
e 5 5 0.0